A Look Inside: Evolving Automation







In my previous blog post, I explored Unified Test Runner (or simply UTR) and Hoarder. In short: UTR is a single entry point we use to run all types of tests both locally and on our CI system - Katana. UTR sends test execution data to a database. We call this database and its surrounding web-services Hoarder. This post is about how UTR and Hoarder helped us make our automation smarter, create new tools, and improve the existing ones.


Hoarder Analytics UI
All the Hoarder data is available through a REST API. We built some applications on top of these API. One of them is the Hoarder Analytics UI. It helps us query different slices of test execution data. Most often we use it to find out:
- Which tests are slow
- Which tests are failing
- When test failed for the first time
- If an unstable test is fixed
- Which tests are newly added
- Which tests never fail
- And much more
For example, we can set up a Filter which tells us the statistics for the AudioClipCanBeLoadedFromAssetBundle test for the Last Month on the branch draft/trunk. Once the filter is specified and the Get Data button is clicked, Analytics UI shows the following information:
- Test name (link to the test execution history)
- Pass rate
- Average execution time
- Time Deviation
- Number of samples

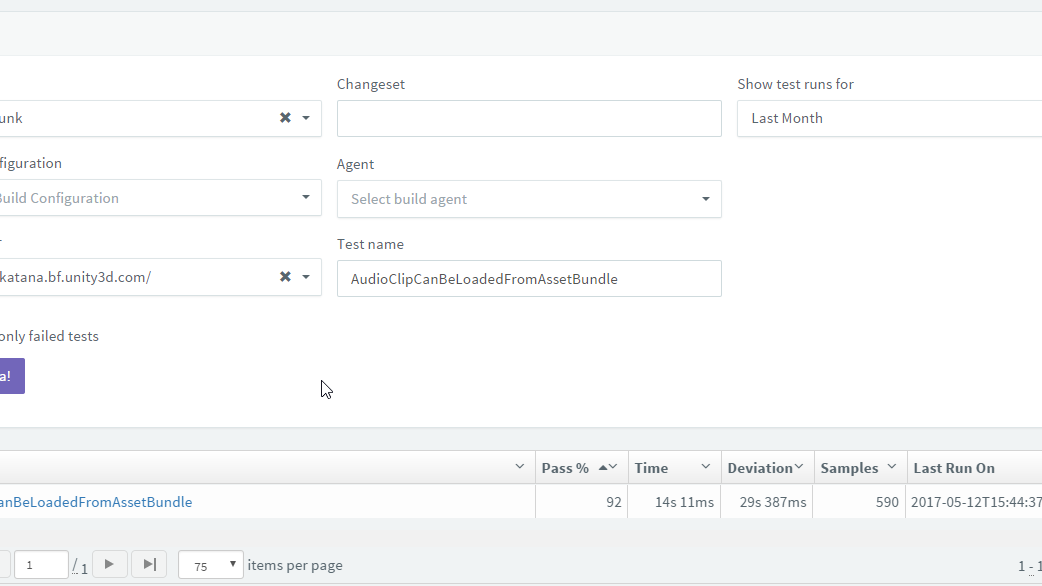
Looking at result above we see that AudioClipCanBeLoadedFromAssetBundle passed in 92% out of 590 executions. It takes ~14 seconds on average. What’s interesting here is that a deviation is almost twice larger than the average execution time. Very often this is a good predictor that the test has some infrastructure issues. Let’s figure out why!
By clicking on the test name we can drill down into the test execution history and find points of failure.


A successful run takes ~7 seconds. But in the case of failure, we wait for almost 2 minutes! If we click on the Build Number link on the failed test run, we will navigate back to Katana. Here we can find out what exactly has failed:


There are thread dump and minidump artifacts. This means that the standalone player running the test has crashed. But still, why did it take 2 minutes to execute the test? The reason was that the test framework was expecting a ‘test finished’ marker, but there wasn’t one due to the player crashing. Besides the actual problem in the standalone player, it’s clear that the test framework should be improved to detect crashes as soon as possible. Every second of test execution time in Katana counts.
Another interesting fact about Hoarder Analytics UI is that while implementing it, we hit some performance vs. testability issues. If you want to know how we approached them read “Stored procedures guided by tests”.
Improved test report
The test execution report is often the first place we use to spot failures. This report is generated based on JSON data produced by Unified Test Runner. The most significant advantage of the JSON format is that we can extend it in any way we want. For example, for every test, we embedded a list of related artifacts produced while running this test. We also inserted a command line to run a failed test locally. So when Katana displays the test execution report, it can use this information:


A similar version of the test report is also available when running tests locally. However, the test report isn’t perfect -- there are still a lot of things that can be improved:
- Highlight artifacts which contain stack traces, script compilation errors or any other failures
- Crash analyzer integration
- Hoarder integration
Graphics Test Tool
Hoarder data helped us build the Graphics Test Tool. Before I jump into it, let me briefly explain the graphics tests. The way graphics tests work is by comparing a rendered image with a reference image. If the rendered image differs too much from the reference image the graphics test fails. For example, if this is what is rendered:


And this one is the correct reference image:

The graphics test fails because the difference between the two images is too big:

We store thousands of graphics reference images in a mercurial repository. If we change some rendering feature, it might require updating hundreds of reference images in the graphics test repository.
The Graphics Test Tool helps solve this problem. It asks Hoarder “Which graphics tests have failed for a given revision?” Knowing the answer, it can fetch all the failed images from Katana. Then it displays combined information via a web-interface, which allows us to quickly spot differences, download and update reference images in the repository. Read more in this dedicated blog post: “Graphics tests, the last line of automated testing.”
Better visibility
Suppose you are a physics developer and you’ve just fixed some bug in the physics part of the unity codebase. Now, when you run the tests, you notice a documentation test failing. Whose fault is this? Is it a known failure or just an instability? Hoarder can answer this question. All that a developer has to do is paste a test name to Hoarder. If based on the data in Hoarder, it can be determined that it is not the developer’s fault and their branch can still be merged to trunk.
User experience analysis
We can see how our employees are running tests locally. Here are top 5 testing frameworks we use to run tests locally (April 2017).
| Framework type | # of runs |
| runtime | 17052 |
| integration | 14162 |
| native | 8932 |
| graphics | 6874 |
| editor | 2154 |
It is possible to drill down further and figure out usage scenarios depending on the framework type. It can give us very useful insights into improving the user experience.
Smart Test Execution
Any pull request must pass automated tests before being merged to trunk or any other production branch. However, we could not afford to run all the tests on each pull request. Therefore we split our tests into 2 categories:
- A Build Verification (ABV) - includes relatively fast and stable tests with a good platform coverage
- Nightly - includes slow regression tests
We required having a green ABV for any pull request targeting trunk or any other release branch. Nightly tests were optional. This saved a lot of execution time but it created a hole through which red nightly tests could get in trunk. For a while, that was a big challenge for us. It is at this point that we introduced a new Queue Verification Process.
We stopped merging pull requests into trunk directly. Instead, we take a number of pull requests and merge them all into a draft repository. We run all our tests on this batch of pull requests. If any tests fail, we use Mercurial bisect to find the point of failure. The pull request that introduced the failure gets kicked out from the batch. The remaining pull requests are merged to trunk. You can read more about it in this dedicated blogpost: “A Look Inside: The Path to Trunk.”
We built Smart Test execution on top of the Queue Verification process. The idea was very simple -- do not run tests which meet the following conditions:
- 100% Successful
- During last month
- >100 test runs
- On all branches
But we still run all test tests in queue verification, trunk and release branches.
UTR and Hoarder played their role here too. Smart Test Execution was implemented by having UTR send Hoarder a list of tests it is going to run. For each test, Hoarder decides whether the test should be run based on the set of rules above.
It could lead to a situation where someone discovers that a test excluded by Smart Test Selection fails when it hits Queue verification. This could be an unpleasant surprise. We address this situation by letting our developers disable Smart Test Selection.

We are also working on making Smart Test Selection smarter about which tests it excludes by analyzing code coverage data.
Even though some people were affected by this situation, overall we saved thousands of hours of Katana’s execution time.
Check out my colleague Boris Prikhodskiy’s talk about this at GTAC: GTAC2016: Using Test Run Automation Statistics to Predict Which Tests to Run.
Fun with charts
Before we started collecting data, we didn’t know exactly how many tests we were running hourly/daily/weekly/monthly. So this was one of the first things we decided to look at. In August 2015 we ran 16,559,749 tests both locally and on Katana. Since then, the company has grown, Katana has grown, and the number of tests we run every day has increased a lot. In March 2017, for comparison, there were 78,312,981 test runs -- 4.5 times more than in August 2015.
If we take a look at the number of tests we run per day, we’ll see the following picture:


The lower numbers of test runs correspond to weekends. It told us two things:
- Some people were using the build farm during the weekends. Maybe because there are more resources available :)
- We would benefit from having a ‘run on weekends’ option in Katana.
Let’s look at how the number of tests run each month changed during 2016:


Why is there a spike in November? Hoarder data can tell us where all these test runs came from:
| Branch | # of runs |
| trunk | 6043317 |
| 5.5/staging | 5328429 |
| draft/trunk | 4272583 |
| 5.3/staging | 1606800 |
| xxx1 | 1362732 |
| xxx2 | 692974 |
| xxx3 | 603495 |
Looking at the top contributors, we can say that we’ve been busy to run tests on trunk and draft/trunk. These tests come from the Queue Verification and Nightly runs on trunk. Nothing surprising.
We can also notice that we run a lot of tests against 5.5/staging. And this was because we released it that month. We also maintain 5.4 and 5.3 and therefore we run some tests there as well.
Let’s look at xxx1. We intentionally removed the real branch name. The story behind this branch was that we updated NUnit to the newest version. It could potentially affect all our NUnit-based test suites. We overused Katana to test it. Hundreds of thousands of test runs could have been avoided if we had better planned this effort. We could have run a set of smoke tests locally before running them all in Katana. It taught us that not everyone thinks of Katana as a shared resource. It was (and still is) an educational problem. There are several ways to solve it. One way is to teach people how to avoid Katana overuse. Another way is to scale up Katana to let people do what is easiest for them. Ideally we should do both.
The stories behind xxx2 and xxx3 may have told us something different. We didn’t investigate these cases though, because they are too old. Instead we are keeping an eye on actual cases. For each case, because we know a source, we can figure out an exact reason and decide what we can do about it.
Just for fun: a test counter device
Hundreds of our employees run tests on tens of platforms producing millions of test runs every day. We decided to build a small device, which shows us how many tests we’ve run since we started measuring this (top number), how many we ran this month (middle number), and today’s runs (bottom number).


The device is made with Raspberry Pi connected via PCI to a LED RGB matrix. All internals are enclosed in a custom-made 3D printed case. It was inspired by one of the bicycle counters installed in Copenhagen.


This device not only reminds us that Katana is a shared resource, but also that automation is a living giant creature which requires care.
Conclusion
UTR and Hoarder became a fertile soil to grow new tools and improve the existing ones. It is not a coincidence. Unification is a powerful technique which often leads to simplicity. Take a look at power sockets. Wouldn’t be nice if there were fewer types of power sockets? At least device vendors would greatly appreciate this.


Therefore by unifying and simplifying the test running process, we unveiled a lot of possibilities to improve our automation. It was easier to build tools knowing there was only one type of socket to plug a tool into the test running process.
UTR and Hoarder continue to shape our automation. They play a significant role in one crucial project we are currently working on -- Parallel Test Execution, which we’ll cover in future blog post.
If you want to hear more about anything I mentioned in this post just write a comment here and follow me (@ydrugalya) on twitter.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies