Introducing ML-Agents Toolkit v0.2: Curriculum Learning, new environments, and more







The Machine Learning team at Unity is happy to announce the release of a new version of Unity Machine Learning Agents Toolkit – v0.2 Beta! With this release, we are improving the toolkit on all fronts: 1- adding new features to both the Unity SDK and Python API; 2- new example environments to build on top of; 3- improvements to our default Reinforcement Learning algorithm (PPO), in addition to many bug-fixes and other smaller improvements. In this post, we will highlight some of the major additions, but for a full list, check out the GitHub release notes. Also visit the GitHub page to download the latest release.
Since we launched v0.1 Beta over two months ago, and it has been wonderful to see projects and games already being made using the Unity ML-Agents Toolkit, as well as all the helpful community feedback. To inspire more creative use cases in machine learning and beyond with ML-Agents Toolkit, we are excited to announce our very first ML-Agents Community Challenge in this post.
New Continuous Control and Platforming Environments
One of the major requests we received was additional example environments to allow developers a greater variety of baselines from which to start building. We are happy to include four new environments in this release. These environments include two new continuous control environments, plus two platforming environments designed to show off our new Curriculum Learning feature (more on that below).
[youtube id="vRPJAefVYEQ"]
New Features: Curriculum Learning, Broadcasting, and a more flexible monitor
Curriculum Learning – Our Python API now includes a standardized way of utilizing Curriculum Learning during the training process. For those unfamiliar, Curriculum learning is a way of training a machine learning model where more difficult aspects of a problem are gradually introduced in such a way that the model is always optimally challenged. Here is a link to the original paper which introduces the ideal formally. More generally, this idea has been around much longer, for it is how we humans typically learn. If you imagine any childhood primary school education, there is an ordering of classes and topics. Arithmetic is taught before algebra, for example. Likewise, algebra is taught before calculus. The skills and knowledge learned in the earlier subjects provide a scaffolding for later lessons. The same principle can be applied to machine learning, where training on easier tasks can provide a scaffolding for harder tasks in the future.


When we think about how Reinforcement Learning actually works, the primary learning signal is a scalar reward received occasionally throughout training. In more complex or difficult tasks, this reward can often be sparse, and rarely achieved. For example, imagine a task in which an agent needs to push a block into place to scale a wall and arrive at a goal. The starting point when training an agent to accomplish this task will be a random policy. That starting policy will likely involve the agent running in circles, and will likely never, or very rarely scale the wall properly to receive the reward. If we start with a simpler task, such as moving toward an unobstructed goal, then the agent can easily learn to accomplish the task. From there, we can slowly add to the difficulty of the task by increasing the size of the wall, until the agent can complete the initially near-impossible task of scaling the wall. We are including just such an environment with Unity ML-Agents Toolkit v0.2, called Wall Area.


To see this in action, observe the two learning curves below. Each displays the reward over time for a brain trained using PPO with the same set of training hyperparameters and data from 32 simultaneous agents. The difference is that the brain in orange was trained using the full-height wall version of the task, and the blue line corresponds to a brain trained using a curriculum version of the task. As you can see, without using curriculum learning the agent has a lot of difficulties, and after 3 million steps has still not solved the task. We think that by using well-crafted curricula, agents trained using reinforcement learning will be able to accomplish tasks otherwise much more difficult, with much less time.

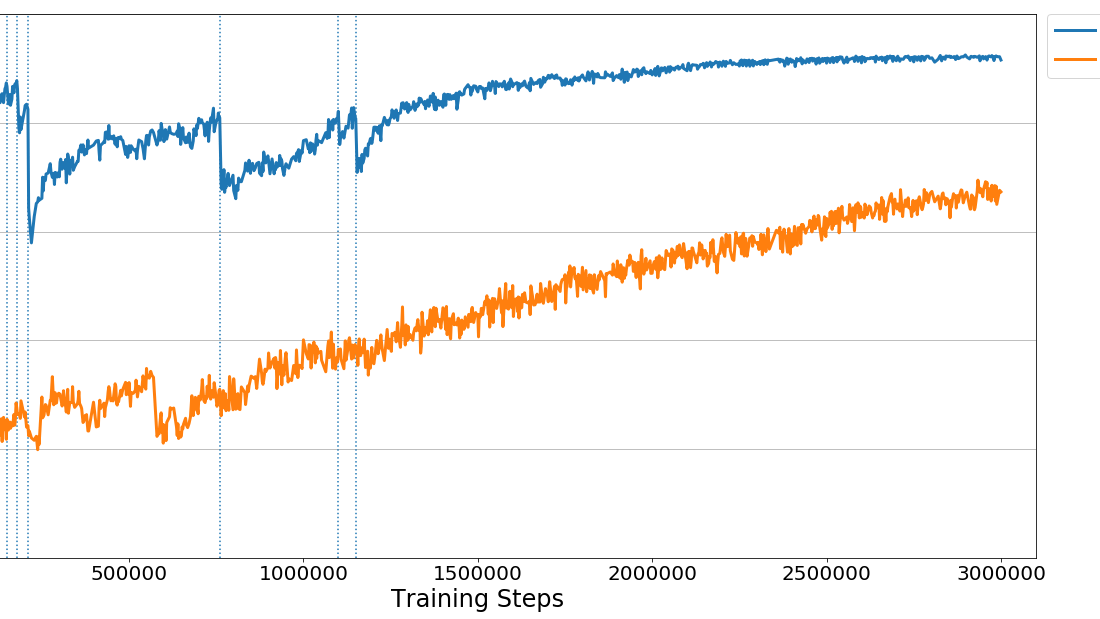
So how does it work? In order to define a curriculum, the first step is to decide which parameters of the environment will vary. In the case of the Wall Area environment, what varies is the height of the wall. We can define this as a reset parameter in the Academy object of our scene, and by doing so it becomes adjustable via the Python API. Rather than adjusting it by hand, we then create a simple JSON file which describes the structure of the curriculum. Within it we can set at what points in the training process our wall height will change, either based on the percentage of training steps which have taken place, or what the average reward the agent has received in the recent past is. Once these are in place, we simply launch ppo.py using the `–curriculum-file` flag to point to the JSON file, and PPO we will train using Curriculum Learning. Of course we can then keep track of the current lesson and progress via TensorBoard.
Here's an example of a JSON file which defines the Curriculum for the Wall Area environment:
{
"measure" : "reward",
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5],
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0]
}
}For those in the community who have created environments which they have had difficulty getting their agents to solve, we encourage you to try Curriculum Learning out, and we would love to hear your findings.
Broadcasting – The internal, heuristic, and player brains now all include a “Broadcast” feature, which is active by default. When active, the states, actions, and rewards for all agents linked to that brain will then be accessible from the Python API. This is in contrast to v0.1, where only the external brain could send information to the Python API. This feature can be used to record, analyze, or store information from these brain types on Python. Specifically, this feature makes imitation learning possible, where data from a player, heuristic, or internal brain can be used as the supervision signal to train a separate network without needing to define a reward function, or in addition to a reward function to augment the training signal. We think this can provide a new avenue for how game developers think of getting intelligent behavior from their systems. In a future blog post, we plan to walk through this scenario and provide an example project.


Flexible Monitor – We have rewritten the Agent Monitor to provide more general usability. Whereas the original Monitor had a fixed set of statistics about an agent which could be displayed, the new Monitor now allows for displaying any desired information related to agents. All you have to do is call Monitor.Log() to display information either on the screen or above an agent within the scene.


As with any beta release, there will likely be bugs and issues. We encourage you to share feedback with us on the GitHub issues page.
Unity ML-Agents Community Challenge
Last but not least, we are excited to announce that Unity will be hosting an ML-Agents Community Challenge. Whether you’re an expert in Machine Learning or just interested in how ML can be applied to games, this challenge is a great opportunity for you to learn, explore, inspire and get inspired.
We want to see how you apply the new Curriculum Learning method. But we’re not looking for any particular genre or style, so get creative! We’ll send some gifts and surprises to the creators who get the most likes at the end of the challenge.
Enter the ML-Agents Challenge
The first round of The Machine Learning Agents Challenge is from Dec 7, 2017 to Jan 31, 2018, and it is open to any developer with basic Unity knowledge and experience. Click this link to enter this challenge. If you’re not familiar with how ML Agents work, please feel free to contact us by mail or on the Unity Machine Learning channel with your questions.
Happy Creating!
[Recommended Readings]
Introducing: Unity Machine Learning Agents Toolkit
Unity AI – Reinforcement Learning with Q-Learning
Using Machine Learning Agents Toolkit in a real game: a beginner’s guide
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies