Introducing Unity Machine Learning Agents Toolkit







Our two previous blog entries implied that there is a role games can play in driving the development of Reinforcement Learning algorithms. As the world’s most popular creation engine, Unity is at the crossroads between machine learning and gaming. It is critical to our mission to enable machine learning researchers with the most powerful training scenarios, and for us to give back to the gaming community by enabling them to utilize the latest machine learning technologies. As the first step in this endeavor, we are excited to introduce Unity Machine Learning Agents Toolkit.
Training Intelligent Agents
Machine Learning is changing the way we expect to get intelligent behavior out of autonomous agents. Whereas in the past the behavior was coded by hand, it is increasingly taught to the agent (either a robot or virtual avatar) through interaction in a training environment. This method is used to learn behavior for everything from industrial robots, drones, and autonomous vehicles, to game characters and opponents. The quality of this training environment is critical to the kinds of behaviors that can be learned, and there are often trade-offs of one kind or another that need to be made. The typical scenario for training agents in virtual environments is to have a single environment and agent which are tightly coupled. The actions of the agent change the state of the environment, and provide the agent with rewards.


The typical Reinforcement Learning training cycle.
At Unity, we wanted to design a system that provide greater flexibility and ease-of-use to the growing groups interested in applying machine learning to developing intelligent agents. Moreover, we wanted to do this while taking advantage of the high quality physics and graphics, and simple yet powerful developer control provided by the Unity Engine and Editor. We think that this combination can benefit the following groups in ways that other solutions might not:
- Academic researchers interested in studying complex multi-agent behavior in realistic competitive and cooperative scenarios.
- Industry researchers interested in large-scale parallel training regimes for robotics, autonomous vehicle, and other industrial applications.
- Game developers interested in filling virtual worlds with intelligent agents each acting with dynamic and engaging behavior.
Unity Machine Learning Agents Toolkit
We call our solution Unity Machine Learning Agents Toolkit (ML-Agents toolkit for short), and are happy to be releasing an open beta version of our SDK today! The ML-Agents SDK allows researchers and developers to transform games and simulations created using the Unity Editor into environments where intelligent agents can be trained using Deep Reinforcement Learning, Evolutionary Strategies, or other machine learning methods through a simple to use Python API. We are releasing this beta version of Unity ML-Agents toolkit as open-source software, with a set of example projects and baseline algorithms to get you started. As this is an initial beta release, we are actively looking for feedback, and encourage anyone interested to contribute on our GitHub page. For more information on Unity ML-Agents toolkit, continue reading below! For more detailed documentation, see our GitHub Wiki.
Learning Environments

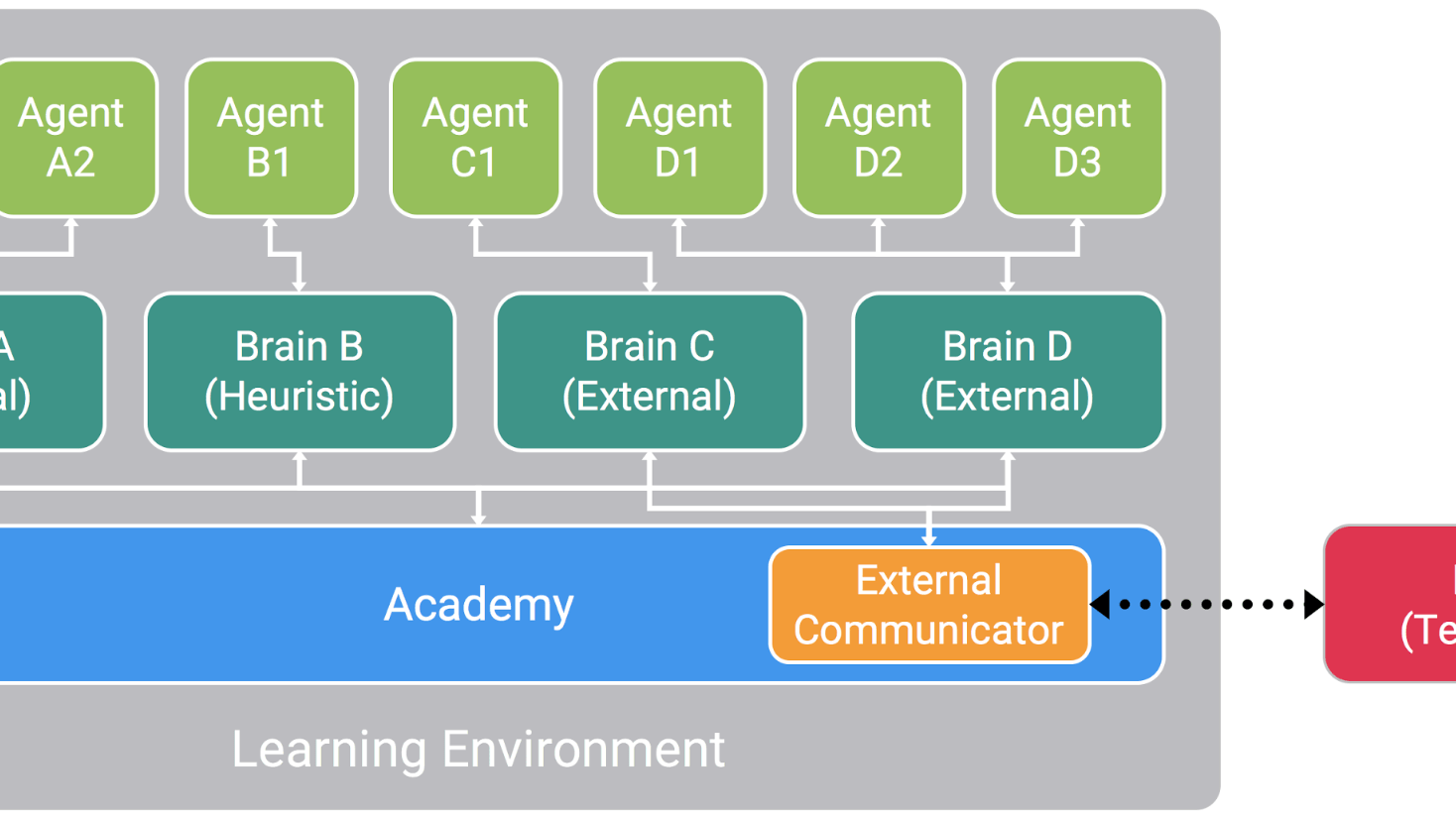
A visual depiction of how a Learning Environment might be configured within Unity ML-Agents Toolkit.
The three main kinds of objects within any Learning Environment are:
- Agent - Each Agent can have a unique set of states and observations, take unique actions within the environment, and receive unique rewards for events within the environment. An agent's actions are decided by the brain it is linked to.
- Brain - Each Brain defines a specific state and action space, and is responsible for deciding which actions each of its linked agents will take. The current release supports Brains being set to one of four modes:
- External - Action decisions are made using TensorFlow (or your ML library of choice) through communication over an open socket with our Python API.
- Internal (Experimental) - Actions decisions are made using a trained model embedded into the project via TensorFlowSharp.
- Player - Action decisions are made using player input.
- Heuristic - Action decisions are made using hand-coded behavior.
- Academy - The Academy object within a scene also contains as children all Brains within the environment. Each environment contains a single Academy which defines the scope of the environment, in terms of:
- Engine Configuration - The speed and rendering quality of the game engine in both training and inference modes.
- Frameskip - How many engine steps to skip between each agent making a new decision.
- Global episode length - How long the episode will last. When reached, all agents are set to done.
The states and observations of all agents with brains set to External are collected by the External Communicator, and communicated to our Python API for processing using your ML library of choice. By setting multiple agents to a single brain, actions can be decided in a batch fashion, opening the possibility of getting the advantages of parallel computation, when supported. For more information on how these objects work together within a scene, see our wiki page.
Flexible Training Scenarios
With Unity ML-Agents toolkit, a variety of training scenarios are possible, depending on how agents, brains, and rewards are connected. We are excited to see what kinds of novel and fun environments the community creates. For those new to training intelligent agents, below are a few examples that can serve as inspiration. Each is a prototypical environment configurations with a description of how it can be created using the ML-Agents SDK.
- Single-Agent - A single agent linked to a single brain. The traditional way of training an agent. An example is any single-player game, such as Chicken. (Demo project included - “GridWorld”)
- Simultaneous Single-Agent - Multiple independent agents with independent reward functions linked to a single brain. A parallelized version of the traditional training scenario, which can speed-up and stabilize the training process. An example might be training a dozen robot-arms to each open a door simultaneously. (Demo project included - “3DBall”)
- Adversarial Self-Play - Two interacting agents with inverse reward functions linked to a single brain. In two-player games, adversarial self-play can allow an agent to become increasingly more skilled, while always having the perfectly matched opponent: itself. This was the strategy employed when training AlphaGo, and more recently used by OpenAI to train a human-beating 1v1 Dota 2 agent. (Demo project included - “Tennis”)
- Cooperative Multi-Agent - Multiple interacting agents with a shared reward function linked to either a single or multiple different brains. In this scenario, all agents must work together to accomplish a task than couldn’t be done alone. Examples include environments where each agent only has access to partial information, which needs to be shared in order to accomplish the task or collaboratively solve a puzzle. (Demo project coming soon)
- Competitive Multi-Agent - Multiple interacting agents with inverse reward function linked to either a single or multiple different brains. In this scenario, agents must compete with one another to either win a competition, or obtain some limited set of resources. All team sports would fall into this scenario. (Demo project coming soon)
- Ecosystem - Multiple interacting agents with independent reward function linked to either a single or multiple different brains. This scenario can be thought of as creating a small world in which animals with different goals all interact, such a savanna in which there might be zebras, elephants, and giraffes, or an autonomous driving simulation within an urban environment. (Demo project coming soon)
Additional Features
Beyond the flexible training scenarios made possible by the Academy/Brain/Agent system, the Unity ML-Agents toolkit also includes other features which improve the flexibility and interpretability of the training process.
- Monitoring Agent’s Decision Making - Since communication in Unity ML-Agents toolkit is a two-way street, we provide an Agent Monitor class in Unity which can display aspects of the trained agent, such as policy and value output within the Unity environment itself. By providing these outputs in real-time, researchers and developers can more easily debug an agent’s behavior.

Above each agent is a value estimate, corresponding to how much future reward the agent expects. When the right agent misses the ball, the value estimate drops to zero, since it expects the episode to end soon, resulting in no additional reward.
- Curriculum Learning - It is often difficult for agents to learn a complex task at the beginning of the training process. Curriculum learning is the process of gradually increasing the difficulty of a task to allow more efficient learning. The Unity ML-Agents toolkit supports setting custom environment parameters every time the environment is reset. This allows elements of the environment related to difficulty or complexity to be dynamically adjusted based on training progress.

Different possible configurations of the GridWorld environment with increasing complexity.
- Complex Visual Observations - Unlike other platforms, where the agent’s observation might be limited to a single vector or image, the Unity ML-Agents toolkit allows multiple cameras to be used for observations per agent. This enables agents to learn to integrate information from multiple visual streams, as would be the case when training a self-driving car which required multiple cameras with different viewpoints, a navigational agent which might need to integrate aerial and first-person visuals, or an agent which takes both a raw visual input, as well as a depth-map or object-segmented image.


Two different camera views on the same environment. When both are provided to an agent, it can learn to utilize both first-person and map-like information about the task to defeat the opponent.
- Imitation Learning (Coming Soon) - It is often more intuitive to simply demonstrate the behavior we want an agent to perform, rather than attempting to have it learn via trial-and-error methods. In a future release, the Unity ML-Agents toolkit will provide the ability to record all state/action/reward information for use in supervised learning scenarios, such as imitation learning. By utilizing imitation learning, a player can provide demonstrations of how an agent should behave in an environment, and then utilize those demonstrations to train an agent in either a standalone fashion, or as a first-step in a reinforcement learning process.
An Evolving Platform
As mentioned above, we are excited to be releasing this open beta version of Unity Machine Learning Agents Toolkit today, which can be downloaded from our GitHub page. This release is only the beginning, and we plan to iterate quickly and provide additional features for both those of you who are interested in Unity as a platform for Machine Learning research, and those of you who are focused on the potential of Machine Learning in game development. While this beta release is more focused on the former group, we will be increasingly providing support for the latter use-case. As mentioned above, we are especially interested in hearing about use-cases and features you would like to see included in future releases of Unity ML-Agents Toolkit, and we will be welcoming Pull Requests made to the GitHub Repository. Please feel free to reach out to us at ml-agents@unity3d.com to share feedback and thoughts. If the project sparks your interests, come join the Unity Machine Learning team!
Happy training!
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies