Unity における模倣学習 ― ワークフロー







ML-Agents v0.3 ベータ版が公開され、機械学習を新しく様々な形でプロジェクトに使用できるようになりました。ゲーム開発、シミュレーション、アカデミック、その他どんなタイプのプロジェクトにも、仮想環境内へのニューラルネットワークを使用は利益をもたらします。
この最新版が公開される前から ML-Agents を使用されていた皆様は、強化学習とは何か既にご存知のことと思います。初めて使用される方は、私の以前作成したビギナーズガイドをご覧になることをお勧めします。本記事は、強化学習の代替となる大きな機能のひとつである、模倣学習ついて理解できる内容となっています
はじめに
強化学習は報酬と罰を用いた仕組みによって機能するものですが、模倣学習は教師エージェント(タスクを行う)と生徒エージェント(教師を模倣する)を用いた仕組みで機能します。これは、AI を機械のように完璧に振る舞わせるのではなく、実際の人間のように振る舞わせたい場合に非常に有用です。ここで、今年の GDC での Unity の基調講演でご紹介したデモ動画(英語)をご覧ください。
挙動を記述する代わりに機械学習エージェントを使用するメリットは、機械学習エージェントには順応性があることと、AI 開発の知識がほぼ必要ないことです。
ML-Agents v0.1 または v0.2 を用いたプロジェクトから始められる場合で本記事をリファレンスとして使用したい場合は、セマンティクスに対する変更をご確認の上 v0.3 に合わせるようにしてください。Unity の開発環境に ML-Agents を設定するためのガイドが必要な方は ML-Agents のドキュメントを利用ください。
タスク
このデモは、Cybernetic Walrus 制作のゲーム『Antigraviator』のアセットを使用して Unity が開発したプロジェクト『Hover Racer』をベースにしたものです。GDC でご紹介したシーンを見ながら、その機能する仕組みを確認して行きましょう。

ここでのタスクは、プレイヤーが敵の車との競争を楽しく行えるように、その動きを自動化することです。この場合、車がエージェントとなります。AI は、我々のように「見る」ことはできません。そのため、人間がどのような意思決定を行ったか AI が把握するためには、AI は何らかの形で視覚のシミュレーションを行う必要があります。ここでは両方の車が、壁がどこにあるかを「見る」ために、周囲に一連のレイキャストを投射します。これにより、機械は人間が壁を避けていることを認識でき、挙動の模倣を開始できます。もちろん、人間が意図的に壁や他のプレイヤーに追突したりすれば、それを模倣する AI を作ることも可能です。それも面白さのひとつです!
トレーニングの準備
タスクが明確になったところで、トレーニングの準備を開始しましょう。ここで最も重要なことは、トレーニングの開始前に前にタスクを明確にする(そして練習する)ことです。そうすれば、後々苦労しないで済みます。生徒エージェントにタスクを教えて行く訳ですから、まずは自分が理解している必要があります。
まず、観測とアクションについて理解してください。前者は、正常にトレーニングされるためにエージェントが必要とする情報です。ここではエージェントは、障害物を回避するための(障害物が周囲にあるかどうかの)情報を必要とします。この情報を CollectObservations() メソッド内に追加します。Raycast() はカスタムクラス ShipRaycaster 内の単純なメソッドで、エージェントの周囲にレイを投射し、レイが当たった壁からの距離を値として返します。当たらなかった場合は -1 を返します。壁に当たった場合はそこからの距離の値を渡し、何にも当たらなかった場合は -1 の値を渡します。基本的には、観測は 0 から 1 の正規化された値として渡すべきなので、壁までの距離の情報と、レイキャスターが壁に当たったかどうかの情報を両方ブレインに伝える必要があります。したがって、ひとつのレイキャストにつき 2 種類のデータを使用します。例えば、レイキャストの距離が 20 ユニットで、10 ユニット離れた場所で壁に当たった場合、渡す値は .5f(距離の半分)および 1f(YES、衝突あり)になります。この同じレイがどの壁にも当たらなかった場合は、渡す値は 1f(最大距離)および 0f(NO、衝突なし)となります。
また、localVelocity および、localAngularVelocity の Y 値も、ニューラルネットワークに認識させるために記録する必要があります。
//エージェントがそのアクションの結果を受け取る
public override void CollectObservations()
{
//壁が見えるかどうか各レイキャスターに確認する
foreach (ShipRaycaster ray in rays)
{
float result = ray.Raycast();
if (result != -1)
{
AddVectorObs(result);
AddVectorObs(1f);
}
else
{
AddVectorObs(1f);
AddVectorObs(0f);
}
}
Vector3 localVelocity = transform.InverseTransformVector(rigidBody.velocity);
Vector3 localAngularVelocity = transform.InverseTransformVector(rigidBody.angularVelocity);
AddVectorObs(localVelocity.x);
AddVectorObs(localVelocity.y);
AddVectorObs(localVelocity.z);
AddVectorObs(localAngularVelocity.y);
}ここで、この情報を Brain の Inspector ウィンドウに伝えます。この時点でブレインが必要とする情報は、受け取る観測の数と、それらが Discrete と Continuous のどちらであるかです。ここでは、受け取る観測の数は 20 になります。([内訳]レイの配列が 8 つのレイキャストを含んでおり、各レイキャストにつき 2 つ追加するため、合計の観測数が 16 になります。これに更に localVelocity(X・Y・Z 軸)と localAngularVelocity(Y 軸)用の 4 つの観測が追加されます。)


アクション(Action)とは、トレーニング中およびテスト(再生モード)中にエージェントが実行できる動作のことです。アクションは Discrete か Continuous のどちらかに設定できます。ここでは、連続的(Continuous)なアクションがひとつ(操縦)しかありません。これは、負の値(左に操縦)または正の値(右に操縦)を持つことができ、AgentAction() メソッド内に記述できます。さらに、トレーニンを行う人間用の視覚的フィードバックとして機能するちょっとした報酬を含めることもできます。この報酬はトレーニングには影響を及ぼしません。トレーニング中にコンソールに出力することで、エージェントが実際に学習していることをトレーナーに通知するものです。
//エージェントが意思決定を行う
public override void AgentAction(float[] act, string txt)
{
movement.input.rudder = Mathf.Clamp(act[0], -1, 1);
AddReward(.1f);
}再度、この情報を Brain の Inspector ウィンドウに送信します。

エージェントが理解すること、およびエージェントが行えることは、最初から明確にする必要があります。Agent クラスの記述と Brain コンポーネントの変数の記入は密接に関連しています。
エージェントの記述を終える前にもうひとつ必要な作業は、車が障害物に衝突した時に確実にシミュレーションが再開されるようにすることです。これを行うには、壁との衝突を確認チェックします。Done() が呼び出されると、AgentReset() メソッドがエージェントのリセットを行い、再び学習を開始できるようにします。つまり、最も近いウェイポイントに車を戻して一切の速度をゼロにします。。
//Agentが壁と衝突し、走路上での再スタートが必要となる
public override void AgentReset()
{
transform.position = spawnPosition;
transform.rotation = spawnRotation;
rigidBody.velocity = Vector3.zero;
rigidBody.angularVelocity = Vector3.zero;
}教師エージェントと生徒エージェント
目的は、教師レーサーを模倣するように生徒レーサーをトレーニングすることです。したがって、この 2 つのエージェントにそれぞれ生徒ブレインと教師ブレインを関連付けて実装する必要があります。これは単純に現在シーン内にあるブレインを複製するだけで行えます。なぜならインスペクター内の変数は両方とも同じはずだからです。ここで重要なのは、後々の事を考えて、ブレインがアタッチされているゲームオブジェクトに関連した名前を付けることです。“StudentBrain” と “TeacherBrain” のような名前は適切です。
 | 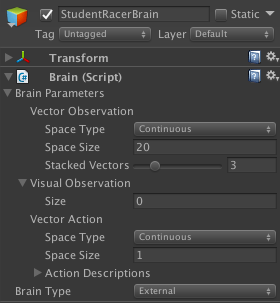 |
Teacher の Brain Type は “Player” です。プレイヤーから来る入力を使用しているからです。ここでは、操縦の入力をゲームのロジック内で定義されている通りに設定しています。A キーが左方向への操縦(値 -1)で D キーが右方向への操縦(値 1)です。“Broadcast” というチェックボックスを有効にすると、プレイヤーが実行したアクションが Student のブレインから確実に見えるようになり、模倣学習できるようになります。
トレーニングを受けるのは Student のブレインです。Student の Brain Type は “External“ になります。つまり、そのプレイ中の挙動が AI のブレインによって決定されるということです。
トレーニングの設定(ハイパーパラメーター)は python フォルダー内の trainer_config.yaml ファイルを編集することでカスタマイズ可能ですが、初期値を使用することもできます。トレーニングが開始されると、各ブレインの設定はこのファイル内の名前によって特定されます。このため、エディター内でブレインのゲームオブジェクト名に注意を払うことが重要です。trainer_config.yaml ファイル内の StudentBrain は以下のように表示されます。
StudentBrain: trainer: imitation max_steps: 10000 summary_freq: 1000 brain_to_imitate: TeacherBrain batch_size: 16 batches_per_epoch: 5 num_layers: 4 hidden_units: 64 use_recurrent: false sequence_length: 16 buffer_size: 128
トレーニングのプロセス
次は、トレーニングを開始してエージェントの訓練を始めるステップです。まず、Unity の実行ファイルを python フォルダー内にビルドしてください。次に、ターミナルウィンドウから python フォルダーに移動して python3 learn.py <env_name> --train --slow を実行してください。<env_name> は Unity の実行ファイルの名前です。ウィンドウがポップアップ表され、教師エージェントとしてプレイできるようになります。生徒エージェントが自分でタスクを実行できるようになるまでトレーニングを続けてください(これ位の難易度のタスクの場合、4-5 分もあれば十分なはずです)。
トレーニングが完了したら、CTRL+C を押してシミュレーションを終了してください。トレーニングされたモデル(特定の観測に対して実行するアクション)を含む .bytes ファイルがプログラムによって出力されます。Student の Brain Type を Internal に変更すると、このファイルがエディター内にインポートし戻されます。最終的にエージェントはこの動画の 0:32 辺りで見られるような挙動になります。
まとめ
今日、機械学習の世界では沢山の事が起こっています。Unity では、デベロッパーの皆様に機械学習を素早く簡単に利用していただけるように取り組みを重ねています。本記事が、皆様がプロジェクトを開始するに当たって、また Unity における機械学習の可能性を理解するに当たって、少しでも助けになれば嬉しく思います。
この記事が役に立ったと感じられたなら、コメント欄で是非お知らせください。よろしければ皆様がどんなプロジェクトに取り組んでいらっしゃるかも教えてください。また、機械学習ポータルもご利用ください。
Unite Berlin でも機械学習のセッションが予定されています。ご参加予定の方は、こちらもお見逃しなく!
ツールキットについての概略を聞きたい方には、Vincent-Pierre Berges による『Democratize Machine Learning: ML-Agents Explained(3 日目、breakout 3)の聴講をおすすめします。また、Vincent-Pierre は『Hands-On Lab on Machine Learning』(3 日目、breakout 2)というセッションもホストしています。開発中のゲームのマーケティングにご興味のある方は、Juho Metsovuori の『Maximize user acquisition spend with immersive ad formats and machine learning』(2 日目、breakout 4)をチェックしてください。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies