ML-Agents のセルフプレイを使用したインテリジェントな対戦相手のトレーニング







ML-Agents ツールキット(v0.14)の最新リリースに、セルフプレイ機能を追加しました。対戦型ゲーム(片方のエージェントの利益がそのまま他方のエージェントの損失になるゼロサムゲーム)の対戦エージェントをトレーニングできる機能です。このブログ記事では、セルフプレイの概要を説明するほか、ML-Agents ツールキットのサッカーのデモ環境を使用して安定的かつ効果的にトレーニングを実施する例を紹介します。
Unity ML-Agents ツールキットのテニスとサッカーのデモ環境では、エージェント同士が対戦します。このタイプの対戦シナリオでのエージェントのトレーニングは、非常に難しい場合があります。実際、ML-Agents ツールキットの以前のリリースでは、こうした環境で確実にエージェントをトレーニングするには、大規模な報酬のエンジニアリングが必要でした。バージョン 0.14 では、ユーザーがセルフプレイの強化学習(RL)を利用してゲーム内でエージェントをトレーニングできるようになりました。OpenAI Five や DeepMind's AlphaStar など、RL の特に注目度が高い成果の大部分で、基盤となっているメカニズムです。セルフプレイでは、エージェントの現在の「自分」と過去の「自分」を対戦相手として使用します。これにより、自然に改良される対戦相手が生成され、エージェントは従来の強化学習アルゴリズムを使用してそれと対戦することで、徐々に改良されていきます。十分にトレーニングされたエージェントは、人間の上級プレイヤーの対戦相手として使用できます。
セルフプレイの学習環境は、人間が対戦相手を構築する仕組みに似ています。たとえば、テニスを学んでいる人間は、スキルレベルが同程度のプレイヤーを相手にトレーニングを行います。なぜなら、対戦相手のスキルレベルが自分より高すぎても低すぎても、テニスの習得にはつながらないからです。スキルの向上という観点からは、初心者レベルのテニスプレイヤーの場合は、他の初心者レベルのプレイヤーと対戦した方が、赤ちゃんやノバク・ジョコビッチ選手と対戦するよりもはるかに効果的です。赤ちゃんはボールを打ち返すことができず、ジョコビッチ選手は打ち返せないボールを打ってきます。初心者が十分なスキルを身に付けたら、次のレベルとしてトーナメント戦に進み、より強い相手と対戦します。
このブログ記事では、セルフプレイの力学について技術的な詳細を紹介するほか、セルフプレイを例示するためにリファクタリングされたテニスとサッカーのデモ環境の概要について説明します。
ゲームのセルフプレイの歴史
解を求めてゲーム内で人間と対戦するための人工エージェントを構築するという取り組みの中で、セルフプレイという概念には長い歴史があります。このメカニズムの初期の使用例の 1 つとして、Arthur Samuel 氏のチェッカーのプレイシステムが挙げられます。これは、1950 年代に開発され、1959 年に公開されました。このシステムが足がかりになり、RL の画期的な研究成果である Gerald Tesauro 氏の TD-Gammon が 1995 年に公開されました。TD-Gammon では、時間的差分学習アルゴリズム TD(λ) とセルフプレイを併用し、人間のエキスパートに匹敵するバックギャモンエージェントのトレーニングを行いました。場合によっては、TD-Gammon は位置の把握が世界的なプレイヤーよりも優れていることが観測されました。
セルフプレイは、RL における現代の重要な研究成果の多くで重要な役割を果たしています。特に、人間を超えるチェスや碁のエージェントや優秀な DOTA 2 エージェントのほか、レスリングやかくれんぼなどのゲームにおける複雑な戦略や対抗戦略の学習を促進しました。セルフプレイを使用した研究成果において、研究者は、人間のエキスパートを驚かせるような戦略をエージェントが発見することをよく指摘しています。
ゲームでのセルフプレイによって、プログラマーの創造性とは別に、ある程度の創造性がエージェントに身に付きます。エージェントには、ゲームのルールのみが指定され、勝敗条件が指示されます。このような最初の原則を基に、エージェント自身が勝つために有効な行動を見つけ出します。TD-Gammon の制作者の言葉を借りると、「...間違いを生じたり、信頼性が低い場合があったりする人間の先入観や偏見によって、プログラムが阻害されることがなくなる」という意味で、この学習フレームワークは自由です。この自由によって、特定のゲームに対する人間のエキスパートの見方を変えるような効果的な戦略を、エージェントが見つけ出すことができました。
対戦型ゲームでの強化学習
従来の RL の問題では、エージェントは蓄積される報酬を最大化する行動方策を学習しようとします。報酬信号によって、ゴールの状態への到達やアイテムの収集などのエージェントのタスクがエンコードされます。エージェントの動作は、環境の制約を受けます。たとえば、重力、障害物の存在、エージェントのアクションに伴う相対的影響(自身を動かすための力の適用など)はすべて、環境の制約です。これらの制約はエージェントの実行可能な行動を制限し、また、エージェントが大きな報酬を獲得するためにその対処方法を学習する必要がある環境側の強制力となります。つまり、エージェントは最も報酬が大きい状態の連続を経過できるように、環境の力学と対戦します。

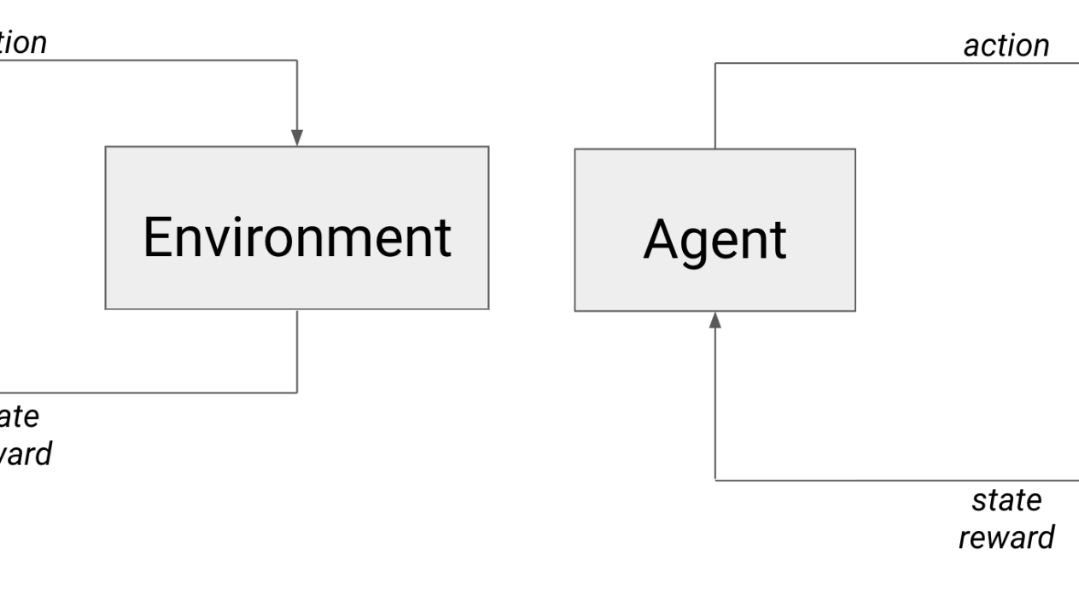
左側は一般的な RL シナリオで、エージェントが環境内で行動し、次の状態と報酬を受け取ります。右側はエージェントが対戦相手と戦う学習シナリオで、対戦相手は、エージェントから見ると実質的には環境の一部です。
対戦型ゲームの場合は、エージェントは環境力学だけでなく、別のエージェント(場合によってはインテリジェントなエージェント)とも戦うことになります。対戦相手は環境に埋め込まれていると考えることができます。なぜなら、その行動が、エージェントが観測する次の状態と受け取る報酬に直接影響するからです。


ML-Agents ツールキットのテニスのデモ環境
ML-Agents のテニスのデモ環境を見てみましょう。青のラケット(左)が学習エージェントで、紫のラケット(右)が対戦相手です。ネットを越えてきたボールを打ち返すために、エージェントは飛んでくるボールの軌道を考慮し、それに合わせてラケットの角度と速度を調整して重力(環境)と戦わなければなりません。ただし、対戦相手がいる場合は、ネットを越えて飛んできたボールを打ち返すだけでは不十分です。対戦相手が強ければ、ウィニングショットが打ち返されてエージェントが負ける場合があります。対戦相手が弱ければ、打ち返したボールがネットに当たることもあります。対戦相手が同レベルの場合は、ボールが打ち返されてゲームが続行します。どの場合でも、次の状態と報酬は、環境と対戦相手の両方によって決まります。ただし、この 3 つの状況すべてで、エージェントは同じように打ち返します。このことが、対戦型ゲームでの学習と対戦エージェントの行動のトレーニングを難しい問題にしています。
適切な対戦相手に関する考慮事項は、小さな問題ではありません。前述の考察で説明したように、対戦相手の相対的な強さは、個々のゲーム結果に大きく影響します。対戦相手が強すぎると、エージェントを一から強化するのは非常に困難になります。一方、対戦相手が弱すぎると、エージェントは勝ち方を学習できるかもしれませんが、そこで学習した行動は、別の対戦相手やより強い対戦相手には役立たない可能性があります。そのため、スキルが同等レベルの対戦相手が必要になります(難しい課題ですが不可能ではありません)。さらに、エージェントは新しいゲームのたびに改善されるため、対戦相手にも同等の技術向上が求められます。


セルフプレイでは、過去のスナップショットまたは現在のエージェントが環境に埋め込まれる対戦相手になります。
セルフプレイは助け舟です。エージェント自身は、適合する対戦相手としての要件も満たします。スキルは(エージェント自身と)ほぼ同等で、徐々に強化されていきます。このケースでは、環境に組み込まれるのはエージェント自身の方策です(図を参照)。カリキュラム学習に精通している方であれば、これは強くなっていく対戦相手とエージェントを戦わせてトレーニングを行うための自然進化カリキュラム(自動カリキュラムとも呼ばれます)と考えることもできます。したがって、セルフプレイを利用すれば、環境を強化して対戦型ゲームの対戦エージェントをトレーニングできます。
以降の 2 つのサブセクションでは、対戦エージェントのトレーニングのより技術的な側面と、ML-Agents ツールキットのセルフプレイの使用法と実装に関する詳細について考えていきます。このブログ記事の要点のみを把握するだけであれば、これら 2 つのサブセクションは飛ばしていただいてかまいません。
実用上の考慮事項
セルフプレイのフレームワークでは、実用するうえでいくつかの問題が生じます。具体的には、特定のプレイスタイルを負かす過適合と、トレーニングプロセスにおける遷移関数の非定常性に起因する不安定さ(常に移動する対戦相手など)です。前者が問題なのは、エージェントを一般的な対戦相手として、さまざまなタイプの相手に対して安定して動作させる必要があるためです。後者を説明するためテニスの環境を例に挙げると、対戦相手ごとに打ち返すボールの角度や速度は異なります。学習エージェントの観点からは、これは、トレーニングが進むにつれて、同じ判断を下しても異なる状態になることを意味します。従来の強化学習アルゴリズムでは、定常遷移関数を前提にしています。残念ながら、前者の問題に対処するためにエージェントにさまざまな対戦相手を供給する場合は、注意しないと後者の問題を悪化させる可能性があります。
これに対処するために、エージェントの過去の方策のバッファを保持し、そこから学習者が長期にわたって対戦する対戦相手のサンプリングを行います。エージェントの過去の方策からサンプリングを行うことで、そのエージェントはさまざまな相手と対戦します。さらに、エージェントが長期にわたって決まった対戦相手とトレーニングを行えるようにすることで、遷移関数を安定させ、より一貫性のある学習環境を創出します。また、こうしたアルゴリズムの側面は、次のセクションで説明するハイパーパラメーターを使用して管理できます。
実装と使用法の詳細
セルフプレイのハイパーパラメーターの選択については、主な考慮事項は、最終方策のスキルレベルおよび普遍性と、学習の安定性のトレードオフです。多様性を低くして、ゆっくりと変化する対戦相手やまったく変化しない対戦相手とのトレーニングを行うと、結果として、多様性を高くして、変化の速い対戦相手とトレーニングを行う場合よりも、学習プロセスの安定性が高まります。利用可能なハイパーパラメーターによって、サンプリングを行った対戦相手として後で使用するためにエージェントの現在の方策を保存する頻度や、新しい対戦相手のサンプリングを行う頻度、保存する対戦相手の数、プールからサンプリングを行った対戦相手ではなくエージェントの現在の自分と対戦する確率を制御します。利用可能なセルフプレイのハイパーパラメーターの使用ガイドラインについては、ML-Agents の GitHub リポジトリにあるセルフプレイに関するドキュメントをご覧ください。
対戦型ゲームでは、学習の進捗を追跡するための指標として、累積的な環境報酬は効果的ではない場合があります。これは、累積報酬は、対戦相手のスキルに完全に依存するためです。特定のスキルレベルのエージェントは、対戦するエージェントのスキルが低ければ報酬が増え、スキルが高ければ報酬が減ります。Unity では、ELO レーティングシステムの実装を提供しています。ゼロサムゲームで、特定の母集団の 2 人のプレイヤー間の相対的な技術レベルを算出するための手法です。指定されたトレーニングの実施中に、この値は安定して増加します。この値は、TensorBoardとその他のトレーニング指標(累積報酬など)を併用して追跡できます。
セルフプレイとサッカーの環境


最近のリリースでは、サッカーのデモ環境向けのエージェントの方策を含めていません。信頼性の高いトレーニングを実施できないためです。ただし、セルフプレイといくつかのリファクタリングを行うことで、重要なエージェントの行動をトレーニングできるようになりました。最も重要な変更点は、エージェントから「プレイヤーの位置」が削除されたことです。これまでは、明示的なゴールキーパーとストライカーが存在し、これらを使用してゲームプレイの外観を整えていました。新しい環境に関する以下の動画では、ゴールキーパーとストライカーが同一ラインに沿ってロールに応じた協調行動を見せていることがわかります。今後は、エージェント自身がこうした位置を学習します。4 つすべてのエージェントの報酬関数は、ゴールを決めた場合に +1.0、ゴールを決められた場合に -1.0 と定義されており、そのほかにエージェントが得点を狙いに行くよう促すため、時間ステップごとに -0.0003 のペナルティを課しています。
重要なのは、サッカーの環境でのエージェントのトレーニングは、明示的なマルチエージェントアルゴリズムやロールの割り当てなしでも協調行動につながるということです。この研究結果は、問題の定式化に注意を払っていれば、シンプルなアルゴリズムで複雑なエージェント行動をトレーニングできることを示しています。そのために大事なのは、エージェントがチームメイトを観察できることです。つまり、エージェントがチームメイトの相対的な位置に関する情報を観測値として受け取ることです。ボールに向かってアグレッシブにプレイすることで、エージェントは暗示的にチームメイトにディフェンスに戻るよう伝達します。また、ディフェンスに戻ることで、チームメイトにオフェンスに出るよう信号を送ることになります。上記の動画は、エージェントがこうした信号を感知し、一般的なオフェンスポジション、ディフェンスポジションについている様子を示しています。
セルフプレイ機能を使用すると、ゲーム内で新しい対戦行動や興味深い対戦行動のトレーニングを行うことができます。セルフプレイ機能をご利用の方は、ぜひ感想をお聞かせください。
次のステップ
この機械学習とゲーム開発が交差するエキサイティングなフィールドで仕事をしたいとお考えの方は、現在複数のポジションで採用中ですので、是非ご応募ください。
本リリースにおいて提供される機能をお使いになったあなたからのご報告をお待ちしております。Unity ML-Agents ツールキットに関するフィードバックについては、以下のアンケートにご記入ください。また、メールにてお気軽にお問い合わせください。バグを発見した場合は、ML-Agents GitHub の issues ページでぜひご報告ください。全般的な問題やご質問については、Unity ML-Agents フォーラムからお問い合わせください。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies