Unity の Perception ツールで合成データを大規模に生成して分析し、機械学習モデルをトレーニング





合成データは、機械学習モデルのトレーニングに必要なラベル付きデータの取得の困難さを軽減します。合成データに関するブログシリーズの第 2 回となるこの記事では、物体検出を例に、合成データセットを生成、解析するための Unity のツールを紹介します。
第 1 回のブログ記事では、コンピュータビジョンタスクのための機械学習モデルをトレーニングするためにラベル付けされた画像を大量に収集することの課題について議論しました。また、Google Cloud AI や OpenAI などの最新の研究では、物体検出などのタスクに対する合成データの有効性が実証されています。
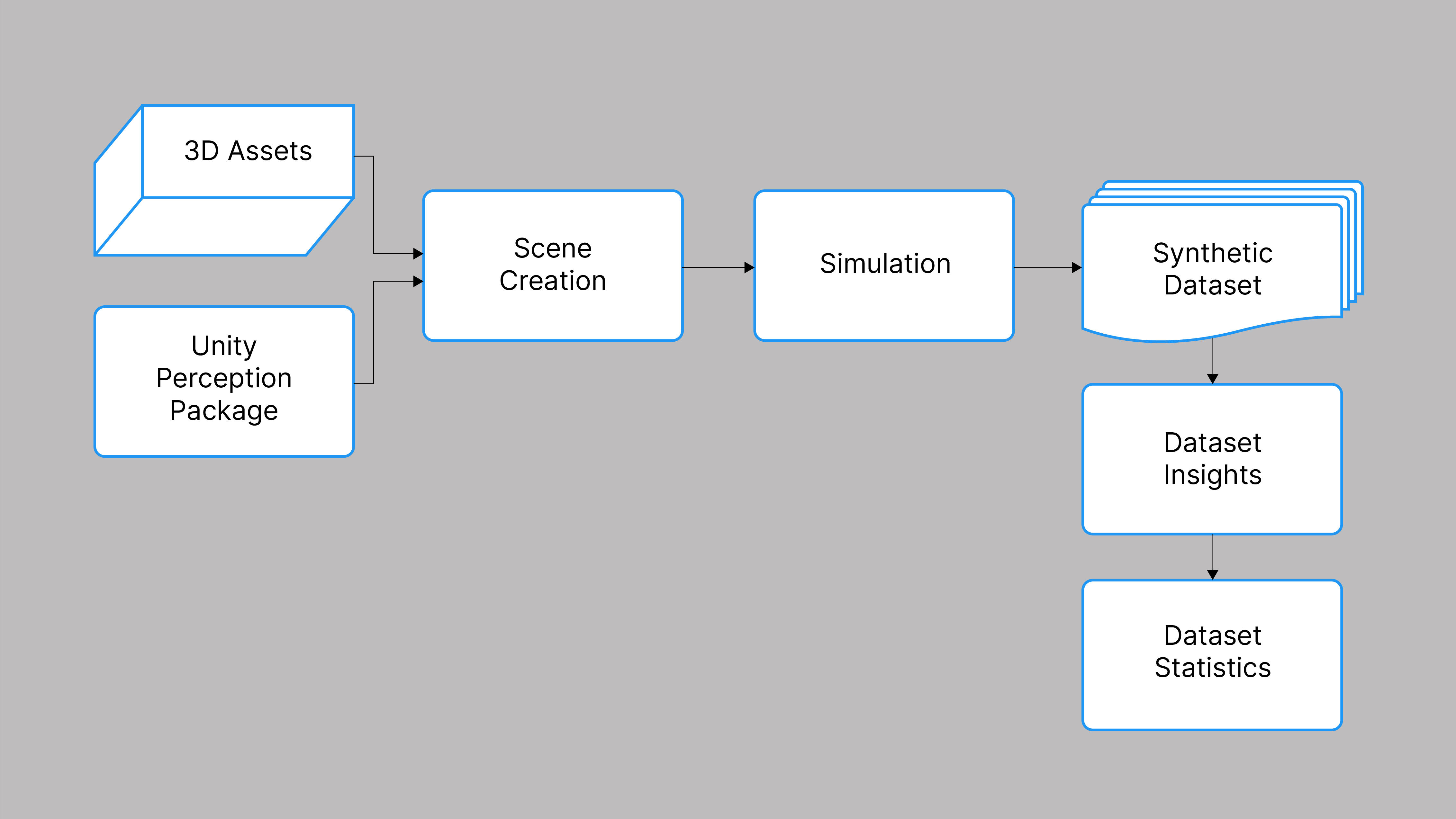
しかし、合成データに関する作業を始めたところから、機械学習モデルをトレーニングするためのデータセットを作成するまでに、越えなければならない数多くのステップがあります。この過程で、開発者はしばしば同様の問題に遭遇し、機械学習モデルを訓練するために必要な質の高いデータを得られないことが多いカスタムのワンオフソリューションを書かざるを得なくなります。今回は、2 つの新しいツールを紹介します。Unity の Perception パッケージと Dataset Insights です。これらのツールは、冗長なステップの多くを削り、質の高い合成データセットの生成、および分析を容易にします。

Unity の Perception ツールで合成データ作成を高速化
Unity Perception パッケージ


Unity の Perception パッケージは、合成データセットを生成するための Unity の新しいワークフローを可能にし、ユニバーサルレンダーパイプラインと HD レンダーパイプラインの両方をサポートしています。この最初のリリースでは、データセットキャプチャのためのツールを提供しており、4 つの主要な機能で構成されています。オブジェクトラベリング、ラベラー、画像キャプチャ、およびカスタムメトリクスの 4 つです。このパッケージは、オブジェクトとラベルの関連付けを入力するためのシンプルなインターフェイスを提供し、それは自動的にピックアップされてラベラーに供給されます。ラベラーはこのオブジェクト情報を使用して、2D バウンディングボックスやセマンティックセグメンテーションマスクなどの正解データを生成します。生成された正解データは、JSON ファイル内の関連するメトリクスと一緒にキャプチャされます。
今後のリリースでは、他の一般的なコンピュータビジョンタスクをサポートするためのインスタンスセグメンテーションなどをサポートするラベラー、シーン生成のためのツール、ドメインのランダム化のための大規模なパラメーターのセットを設定および管理する機能、クラウドでのスケーラビリティといった改良を盛り込んでいく予定です。
Dataset Insights
ラベル付けされたデータの探索と分析は、機械学習の実務家にとって非常に重要です。合成データを扱う場合、クラウドベースのシミュレーション実行で何百万もの画像を生成することができるため、データセットのサイズが非常に早く大きくなることがあります。Dataset Insights という Python パッケージを使って、統計量を計算し、大規模な合成データセットからインサイトを生成するプロセスをシンプルかつ効率的に行うことができます。Dataset Insights は、フレームごとにエクスポートされたメトリクスをローカルまたは管理されたクラウドサービスで消費し、データセット全体について集約された統計情報を可視化することができます。
次のセクションでは、Unity Perception Package と Dataset Insights を使用して合成データセットを作成し、食料品のセットを検出してラベルを付ける物体検出モデルを訓練する目的で使用した方法を説明します。これらのツールは、将来的には他の環境やコンピュータビジョンのタスクにも適用できるように設計されており、より多くの機械学習の実務者が合成データを採用して多様な問題を解決できるようにすることを長期的な目標としています。
3D アセットの作成
Google Cloud AI による最近の研究では、シリアルの箱やペーパータオルなど、店頭で簡単に手に入る 64 種類の食料品を使って、純粋に合成データに基づいて訓練された物体検出モデルの有効性を実証しています。この研究に触発されて、サイズ、形状、質感の多様性において、元の商品と同じかそれに近い商品を同数選びました。
私たちは、デジタルコンテンツ制作(DCC)ツール、スキャンしたラベル、それにフォトグラメトリを使用して、選択した食料品の 3D アセットのライブラリを作成しました。さらに、立方体、球体、円柱などの単純なプリミティブにマッピングされた実世界の画像を使用して、背景と遮蔽物のアセットを作成しました。食料品はすべて、ユニバーサルレンダーパイプラインでシェーダーグラフを使い、Unity エディターで作成したカスタムシェーダーを使用しました。
シーンの作成
私たちは複雑さを増すため、3D アセットの配置のためのビヘイビアを、背景アセットやシェイプとテクスチャで作った注意をそらすための物体と一緒に定義しました.様々な背景を追加することで、このデータセットで学習された機械学習モデルが、実世界で遭遇する可能性のある様々な背景に対応できるようになります。


各レンダーループにおいて、照明、オブジェクトの色相、ぼかし、ノイズのランダム化とともに、前景、背景、遮蔽物のオブジェクトについて、新しくランダムな設定や配置が生成されます。 以下に示すように、Perception パッケージは、データセット内の各画像の RGB 画像、オブジェクトのバウンディングボックス、その他のランダム化パラメーターをキャプチャします。



探索的なデータ分析のための Dataset Insights の使用
大規模な合成データセットの場合、手動で画像を検査してバイアス、欠落したオブジェクトやアーティファクト、意図しないパターンの配置、ポーズなどの異常を検出することは不可能です。
このケースでは、以前に生成されたオブジェクトのデータセットを Dataset Insights Python パッケージに入力して統計量を計算し、機械学習モデルをトレーニングしました。これらのインサイトは、物体検出モデルをトレーニングする目的で画像データが有用であることを確実にする上で非常に効果的であることが証明されました。データセットに対して生成された統計量の例を以下に示します。


私たち自身のテスト中に、いくつかのオブジェクトがフレーム内に複数回出現するという異常に遭遇しました。これは、画像フレーム間のオブジェクト数を可視化したチャートから明らかになりました。この問題を迅速に解決し、データセットの中で対象物が一様に分布していることを確認することで、検出の可能性を均等にすることができました。


データセット全体でオブジェクトが一様に分布していることが望まれますが、機械学習モデルは画像に関心のあるオブジェクトが少なくても、それともある程度数があっても、どちらでも複数のオブジェクトを検出できることを期待しています。上のグラフは、生成されたデータセットの各フレームに含まれるラベル付きオブジェクトの数が、1 フレームあたり 7 個のオブジェクトを中心とした、私たちのよく知る正規分布に従っていることを示しています。


これはさまざまな光源位置を可視化したものです。各点は関心のあるオブジェクトからの光源の相対的な位置を表しています。実世界の照明条件を表現するために、シーン内の光の方向と色を変化させました。上のプロットで示されるように、光源を様々な位置に配置することで、データセット全体でキャプチャされた画像が多様な照明条件とそれに対応する影を持つようにしています。
Unity Simulation による合成データセットのスケーリング
多数の可能な組み合わせでシミュレーションを実行するために、私たちは Unity プロジェクトを実行し、モダンなコンピュータービジョンモデルをトレーニングするために必要な完全なデータセットを生成できるマネージドクラウドサービスの Unity Simulation を使用しました。
このブログシリーズの最終回では、Unity Simulation を使った大規模なデータセットの生成、合成データを使った機械学習モデルのトレーニング、実データでの評価、合成データの経済性、そして今回の経験から得られた重要なポイントについて詳しくご紹介します。
次のステップ
Perception ツールは無料でご利用いただけます。Github で、ツールとオブジェクト検出のサンプルをぜひご覧になってください。
合成データセットをスケールアップさせる方法をお探しの方は、Unity の新サービス Unity Simulation(ベータ版)へのご登録をご検討ください。
皆様からのご意見をお待ちしています。この記事の下にあるコメント欄にコメントをご記入いただくか、perception@unity3d.com までご質問やフィードバックをお寄せください。
* すべての商標はそれぞれの所有者に帰属します。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies