유니티 머신러닝 에이전트 소개







기존에 작성한 두 개의 블로그 게시물에서 게임이 강화 학습 알고리즘 개발을 진전시키는데 수행할 수 있는 역할이 있다고 언급했었습니다. 유니티는 세계에서 가장 널리 사용되는 3D 엔진 개발업체로 머신러닝 및 게임 분야 사이에서 미래를 그려나가고 있습니다. 머신러닝 연구자가 가장 효과적인 훈련 시나리오를 개발하고 이를 통해 게임 커뮤니티가 최신 머신러닝 기술을 활용할 수 있도록 하는 것이 저희 임무의 핵심입니다. 이를 향한 첫 걸음으로 유니티 머신러닝 에이전트를 소개합니다.
지능형 에이전트 훈련
머신러닝은 자율 에이전트에게서 지능형 행동을 끌어낼 수 있는 방식에 변화를 불러오고 있습니다. 과거에는 지능형 행동을 직접 프로그래밍해야 했지만, 이제는 훈련 환경에서 이루어지는 상호작용을 통해 로봇이나 가상 아바타를 비롯한 에이전트에게 훈련을 시키는 방식으로 점점 바뀌고 있습니다. 이 방식은 산업용 로봇, 드론이나 자율 주행 차량은 물론 게임 캐릭터나 적이 어떻게 행동을 해야 할지 학습시키는데 사용됩니다. 이러한 훈련 환경의 질은 에이전트가 학습하는 행동에 중요한 영향을 미치며, 보통 어느 정도 타협이 필요합니다. 가상 환경에서 에이전트를 훈련시키는 시나리오는 보통 특정 환경에 밀접한 연관이 있는 단일 에이전트를 배치하는 것입니다. 에이전트의 행동이 환경의 상태를 바꾸고 에이전트에게 보상을 제공하게 됩니다.


일반적인 강화 학습 훈련 주기
지능형 에이전트를 개발하는데 머신러닝을 활용하려는 사용자가 점점 늘어나고 있는 추세에서, 유니티는 더 유연하고 사용하기 쉬운 시스템을 만들고자 했습니다. 또한, 유니티 엔진과 에디터가 구현하는 섬세한 물리 효과 및 그래픽 효과뿐 아니라 간편하면서도 강력한 개발 도구를 제공하기 원했습니다. 이러한 조합은 다음과 같은 사용자에게 특히 유용합니다.
- 실제 경쟁 및 협업 상황에서 발생 가능한 복잡한 다중 에이전트 행동을 연구하는 학계 연구원
- 로봇공학, 자율 주행 차량 등 산업적 활용을 위한 대규모의 머신러닝에 관심 있는 산업 연구원
- 적극적이고 능동적으로 움직이는 지능형 콘텐츠로 가상 세계를 구축하려는 게임 개발자
유니티 머신러닝 에이전트
이 솔루션은 유니티 머신러닝 에이전트(이하 ML 에이전트)라고 하며, SDK의 오픈 베타 버전을 출시했습니다. ML 에이전트 SDK를 사용하면 유니티 에디터로 제작한 게임이나 시뮬레이션을 심층강화학습(Deep Reinforcement Learning), 진화 전략(evolutionary strategies) 등 머신러닝 방법을 사용하기 쉬운 파이썬 API를 통해 지능형 에이전트를 훈련시킬 수 있는 환경으로 전환할 수 있습니다. 유니티 ML 에이전트의 베타 버전은 오픈 소스 소프트웨어로 출시되며, 참고가 될 만한 예제 프로젝트와 기초적인 알고리즘도 포함되어 있습니다. 최초의 베타 릴리스를 사용해 보고 GitHub 페이지에서 다른 사용자들과 적극적으로 의견을 나누어 주시기 바랍니다. ML 에이전트에 관한 더 자세한 내용이 궁금하시다면 이 포스트를 계속 읽어 보세요. 좀 더 자세한 내용을 다루는 참고 자료는 GitHub 위키페이지에서 확인하실 수 있습니다.
학습 환경

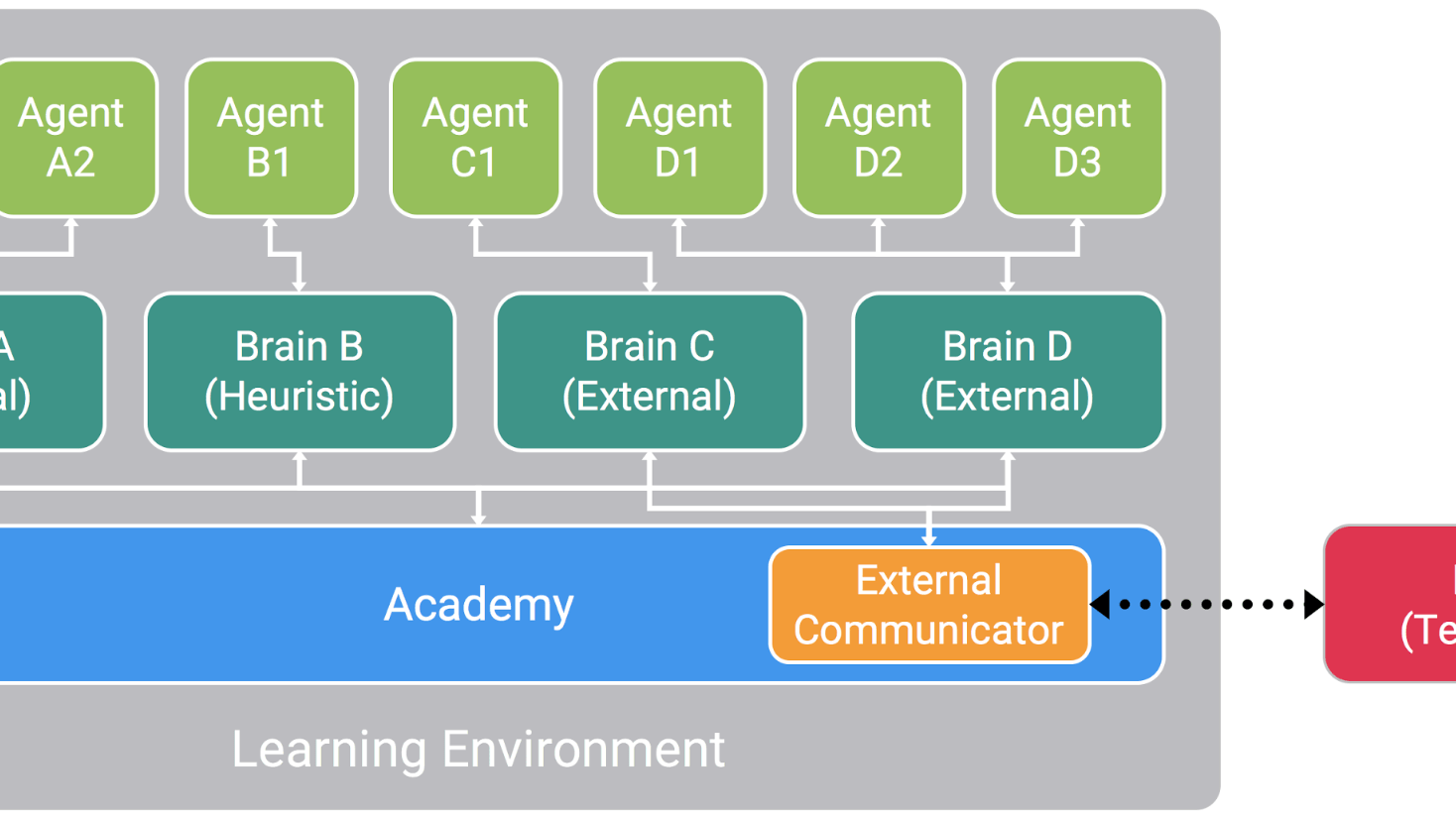
ML 에이전트 내부에 학습 환경이 어떻게 구성될 수 있는지 보여줍니다.s Toolkit.
모든 학습 환경에는 다음과 같이 크게 세 종류의 오브젝트가 있습니다.
- 에이전트 – 각각의 에이전트는 고유의 상태 및 관측 값을 가지고 있고, 환경 내에서 고유의 행동을 하며 환경 내부에서 일어나는 이벤트에 따라 고유의 보상을 받습니다. 각 에이전트의 행동은 해당 에이전트가 연결되어 있는 브레인에 의해 결정됩니다.
- 브레인 – 각 브레인은 특정 상태와 행동 공간을 정의하고, 연결된 에이전트가 어떤 행동을 취할지 결정합니다. 현재 릴리스에서는 브레인을 다음 네 가지 모드로 설정할 수 있습니다.
- External – TensorFlow(또는 기타 원하는 ML 라이브러리)를 사용하여 파이썬 API를 통해 개방형 소켓으로 통신하여 행동을 결정합니다.
- Internal(실험 단계) – TensorFlowSharp를 통해 프로젝트에 탑재된 훈련된 모델을 활용하여 행동을 결정합니다.
- Player – 플레이어의 입력을 통해 행동을 결정합니다.
- Heuristic – 직접 코딩한 동작을 기반으로 행동을 결정합니다.
- 아카데미 – 특정 씬에 있는 아카데미 오브젝트는 해당 환경에 포함된 모든 브레인을 자식으로 포함하고 있습니다. 각 환경은 환경의 범위를 정의하는 한 개의 아카데미를 포함하고 있으며, 그 정의는 다음과 같은 내용을 포함합니다.
- 엔진 설정 – 훈련 및 추론 모드 상에서 게임 엔진의 속도와 렌더링 품질을 설정합니다.
- 프레임스킵 – 각 에이전트가 새로운 결정을 내릴 때 생략할 엔진 단계의 개수를 나타냅니다.
- 글로벌 에피소드 길이 - 에피소드가 지속될 길이를 의미하며, 에피소드가 이 길이에 도달하면 모든 에이전트가 완료 상태로 바뀌게 됩니다.
‘External’로 설정된 브레인에 연결된 에이전트의 상태와 관측값은 External Communicator를 통하여 수집되며, 파이썬 API를 통해 사용자가 선택한 ML 라이브러리에 전달됩니다. 여러 에이전트를 하나의 브레인에 연결할 수 있으면 행동을 배치 방식으로 결정할 수 있어 병렬 컴퓨팅의 장점을 얻을 수도 있습니다. 이러한 오브젝트가 씬 내에서 어떻게 협업하는지 더 알아보려면 유니티 위키 페이지를 참조하세요.
유연한 훈련 시나리오
에이전트, 브레인 및 보상이 연결된 방식에 따라 유니티 ML 에이전트를 통해 다양한 훈련 시나리오를 연출할 수 있습니다. 커뮤니티가 앞으로 어떤 기발하고 참신한 환경을 만들어 나갈지 기대가 됩니다. 지능형 에이전트 훈련이 처음이라면 아래 예제가 도움이 될 것입니다. 각 예제의 환경은 프로토타입 형태로 구성되며, ML 에이전트 SDK를 사용하여 구현하는 방법도 설명되어 있습니다.
- 단일 에이전트 – 하나의 브레인에 연결된 하나의 에이전트. 전형적인 에이전트 훈련 방식으로 치킨 게임을 비롯한 모든 싱글 플레이어 게임을 예로 들 수 있습니다. (데모 프로젝트 - “GridWorld”)
- 동시 단일 에이전트 – 하나의 브레인에 연결된 독립적인 보상 함수를 가지고 있는 여러 개의 독립된 에이전트. 전형적인 훈련 시나리오의 병렬화된 버전으로 훈련 과정의 가속 및 안정화를 꾀할 수 있습니다. 예를 들어 12개의 로봇팔을 훈련시켜 동시에 문을 열게 할 수 있습니다. (데모 프로젝트 - “3DBall”)
- 적대적 자가 플레이 – 서로 대립되는 보상 함수를 갖고 있으며 하나의 브레인에 연결되어 있고 서로 상호작용하는 두 개의 에이전트. 일대일 게임에서 적대적 셀프 플레이를 통해 에이전트가 가장 완벽한 상대인 자기 자신을 대상으로 훈련하여 기술을 더욱 더 연마할 수 있습니다. 알파고(AlphaGo)를 훈련시킬 때 이 전략이 사용되었으며, 최근에 OpenAI에서 프로 선수를 이긴 Dota 2 에이전트를 훈련시킬 때도 동일한 전략이 사용되었습니다. (데모 프로젝트 - “Tennis”)
- 협동형 다중 에이전트 –하나 또는 여러 브레인에 연결되어 있으며 보상 함수를 공유하고 서로 상호작용하는 다중 에이전트. 이 시나리오에서는 단독으로 해낼 수 없는 작업을 수행하기 위하여 모든 에이전트가 협동해야 합니다. 예를 들어 에이전트 각각이 일부 정보만 가지고 있기 때문에 서로 정보를 공유하여 작업을 수행하거나 협동하여 퍼즐을 풀어야 하는 환경 등이 있습니다. (데모 프로젝트 추가 예정)
- 경쟁형 다중 에이전트 – 서로 대립되는 보상 함수를 갖고 있으며 하나 또는 여러 브레인에 연결되어 있고 서로 상호작용하는 다중 에이전트. 이 시나리오에서 에이전트는 서로 경쟁하여 승리를 취하거나 한정적인 자원을 확보해야 합니다. 모든 팀 스포츠가 이 시나리오에 해당됩니다. (데모 프로젝트 추가 예정)
- 생태계 – 독립적인 보상 함수를 갖고 있으며 하나 또는 여러 브레인에 연결되어 있고 서로 상호작용하는 다중 에이전트. 이 시나리오는 얼룩말, 코끼리, 기린이 함께 살고 있는 사바나와 같이 각기 다른 목표를 가진 동물들이 서로 상호작용하는 작은 세계를 만들거나, 도심에서의 자율 주행 시뮬레이션을 구현하는 경우를 예로 들 수 있습니다. (데모 프로젝트 추가 예정)
추가 기능
-
ML 에이전트는 아카데미/브레인/에이전트 시스템을 통해 훈련 시나리오의 유연성을 높일 뿐만 아니라 훈련 과정의 유연성과 해석력을 향상시키는 다양한 기능을 제공합니다.
- 에이전트의 의사결정 모니터링 – ML 에이전트의 통신은 양방향으로 이루어지기 때문에, 유니티는 Agent Monitor 클래스를 제공하여 유니티 환경 자체에서 정책 또는 수치 출력값 등 훈련된 에이전트의 양상을 표시합니다. 연구자와 개발자는 실시간으로 제공되는 이러한 정보를 바탕으로 에이전트의 행동에서 버그를 더욱 쉽게 수정할 수 있습니다.

각 에이전트 상단에 적혀있는 숫자는 해당 에이전트가 예상하는 보상 기대값을 나타냅니다. 우측에 있는 에이전트가 공을 놓치면 기대값이 0으로 떨어지는데, 이는 현재 에피소드가 곧 종료되어 추가 보상을 기대할 수 없게 되기 떄문입니다.
- 커리큘럼 학습 – 에이전트가 훈련 과정 시작부터 복잡한 작업을 학습하기는 일반적으로 쉽지 않습니다. 커리큘럼 학습은 더 효율적인 학습을 위하여 점진적으로 작업의 난이도를 높이는 방식입니다. ML 에이전트는 환경이 초기화될 때마다 사용자 지정 환경 파라미터를 설정하는 것을 지원합니다. 이 기능을 통해 훈련 과정에 따라 난이도 또는 복잡성에 관련된 환경 요소를 동적으로 조정할 수 있습니다.

복잡성이 점차 증가하도록 GridWorld 환경을 다양하게 설정할 수 있습니다.
- 복잡한 시각적 관측 – 에이전트가 단일 벡터나 이미지만 관측하는 타 플랫폼과 달리 ML 에이전트는 각 에이전트가 여러 개의 카메라를 활용하여 관측할 수 있도록 합니다. 이를 통해 서로 다른 시점을 보여주는 여러 카메라가 필요한 자율 주행 차량을 훈련시키는 상황이나 공중 및 1인칭 시점을 조합해야 하는 내비게이션 에이전트, 원시 이미지와 깊이 지도나 객체로 구분된 이미지를 동시에 입력받는 에이전트 등에서 여러 시각적 정보를 통합할 수 있습니다.


같은 환경을 보여주는 두 개의 카메라 시점. 이 두 가지 시점을 에이전트에게 보여주면 에이전트는 1인칭 정보 및 지도와 유사한 정보를 활용하여 상대방에게 승리할 수 있는 법을 학습하게 됩니다.
- 모방 학습 (출시 예정) – 스스로 시행착오를 겪게 하여 학습시키는 것보다는 간단하게 에이전트에게 원하는 행동을 보여주는 방법이 더 나은 경우가 많습니다. 향후 출시될 ML 에이전트에서는 모든 상태/행동/보상 정보를 기록하여 모방 학습 등의 지도 학습 시나리오에서 사용할 수 있는 기능을 제공할 예정입니다. 사용자는 모방 학습을 활용하여 에이전트가 특정 환경에서 어떻게 행동해야 할지 시범을 보여 에이전트를 훈련시키거나 강화 학습 과정의 첫 단계를 시작할 수 있습니다.
진화하는 플랫폼
위에서 언급한 것과 같이 유니티 머신러닝 에이전트의 오픈 베타 버전을 출시했습니다. 베타 버전은 GitHub 페이지에서 다운로드하실 수 있습니다. 이번 출시는 단지 시작에 불과합니다. 머신러닝 연구를 위한 플랫폼으로 유니티를 고려하고 있거나 게임 개발 환경에서 어디까지 머신러닝을 활용할 수 있을지 궁금해하시는 모든 분들을 위해 신속한 테스트를 거쳐 추가 기능을 제공할 예정입니다. 이번 베타 릴리스는 일단 전자에 더 집중하였지만 후자를 위한 지원도 점진적으로 늘릴 계획입니다. 또한 사용 사례나 향후 유니티 ML 에이전트에 추가되었으면 하는 기능이 있으면 적극적으로 공유해 주시기 바라며, GitHub Repository를 통한 Pull Request도 언제든지 환영합니다. 의견 및 문의사항은 ml-agents@unity3d.com으로 보내 주시기 바랍니다. 이 프로젝트에 관심이 있으시다면 유니티 머신러닝 팀에 지원해 보세요.
다음에 또 뵙겠습니다!
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies