Synthetic data: Simulating myriad possibilities to train robust machine learning models




Synthetic data helps many organizations overcome the challenge of acquiring labeled data needed for training machine learning models. This blog kicks off our series on synthetic data for training computer vision systems. In this first post, we will provide a brief overview of synthetic data and the breadth of use cases it enables.
Almost every industry has been touched by the promise of Machine Learning (ML) over the last few years. However, gathering high-quality labeled data to train ML models continues to be a major challenge. A recent survey found 96% of enterprises encounter training data quality and labeling challenges in machine learning projects.
Factors that make it difficult for an organization to collect sufficient labeled data necessary for robust ML models include:
- Privacy and regulatory concerns. For example, video footage within a retail store may contain facial information, which is considered personally identifiable and governed by various regulations.
- Non-exhaustive examples of real-world scenarios leading to selection bias in ML models. For example, a dataset containing examples of an object in a singular pose may lead to an ML performing poorly on the same object seen in a very different pose.
- Corner cases which are rare, expensive, or dangerous to recreate in real life. For example, unusual obstacles or extreme weather conditions on a road that may not have been seen during training, by an autonomous vehicle.
Synthetic data is emerging as an answer to solving many of these challenges. Researchers at OpenAI (Tobin et al., 2017) and Google (Hinterstoisser et al., 2019) have successfully demonstrated the efficacy of synthetic data for real-world tasks such as object detection. With advances in graphics processing and reduction in scalable computing costs, it has become possible to leverage the same tools and systems that are used to develop immersive video games and movies, to simulate photorealistic synthetic images of the real-world. Here we illustrate an example of creating highly realistic images of household products from 3D objects using the Unity engine.
3D assets in Unity*
 A photorealistic synthetic image generated from 3D models*
A photorealistic synthetic image generated from 3D models*
 Labeled synthetic images*
Labeled synthetic images*
Images, thus generated, are also labeled at no extra cost and can be used as training data for computer vision algorithms. These algorithms can be applied to several real-world applications spanning multiple industry verticals, some of which are illustrated below.
Robotic automation in warehouse & logistics
Tasks such as pick-and-place and depalletization of heavy objects in environments such as e-commerce distribution centers are not only repetitive but also hazardous. The introduction of robots in such environments have made our supply chains safer and more efficient. However, warehouse robots continue to face the challenge of recognizing diverse products that vary in size, shape, and weight, on an ongoing basis. By creating synthetic images of new product variants, the cost and turnaround time to gather labeled training data can be reduced significantly. Research from Open AI demonstrates the efficacy of synthetic data for training robots on complex manipulations and performing them in the real world.

Cashierless checkout in retail
Another interesting example are the cashierless checkout stores in retail. Through the use of overhead cameras and weight sensors on shelves, retail chains can track people and products in a privacy-compliant way. By using realistic images of product SKUs and simulating complex in-store shopper behavior such as picking items from a shelf, removing or swapping an item from a cart, a computer vision model can more accurately detect nuanced real-world scenarios and create a positive experience for the shopper and the retailer. There is concrete evidence to demonstrate that computer vision models trained purely on synthetic data perform well on grocery products.
 Ceiling-mounted cameras make cashierless checkout possible in Amazon Go stores (Image credit: SounderBruce)
Ceiling-mounted cameras make cashierless checkout possible in Amazon Go stores (Image credit: SounderBruce)
Visual quality inspection in manufacturing
Other valuable areas could benefit from synthetic data, such as manual quality inspection on a product assembly line. It is a tedious and error-prone exercise to which modern computer vision based automation has brought tangible efficiency gains. However, achieving a high level of precision during the automated inspection process requires significant amounts of data to represent a wide variety of scenarios. Imagine the number of variables an assembly line that is packing bottles of hot sauce has to learn: the possible distortions in labels, missing information, levels of sauce in the bottle, any discoloration of the sauce, among others. These anomalies infrequently occur in the real world. By simulating a large number of such anomalies and generating a large enough dataset to encompass all plausible real-world situations, an ML model can be made more robust.
 Image credit: OAL
Image credit: OAL
In the next installment of this blog series, we will share more information on how you can leverage tools from Unity to generate large scale synthetic datasets and train a machine learning model for tasks such as object detection.
Interested in learning more?
Start generating your own synthetic data with Unity Computer Vision and Unity Simulation. You can also watch this GTC 2020 session to learn more about how to use synthetic data to efficiently train computer vision models.
We would love to hear from you – leave a comment below, or contact us at computer-vision@unity3d.com for questions/feedback.
* All trademarks are the property of their respective owners
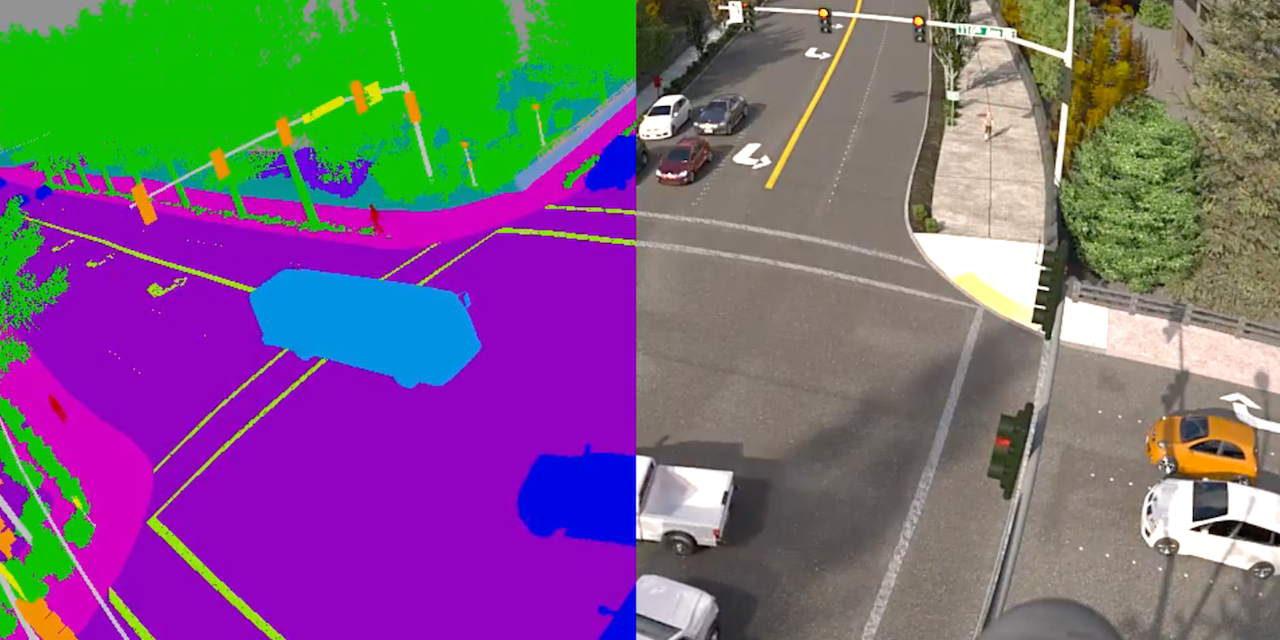
Header image created in collaboration with CVC Barcelona and the City of Bellevue
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies