Unity를 이용한 로봇 비전 학습





로보틱스 분야는 무한한 발전 가능성이 있습니다. 센서 노이즈부터 오브젝트의 정확한 위치 선정까지, 로봇이 정확하고 확실하게 작업을 수행하기 위해서는 주변 환경을 반드시 이해해야 합니다. 지난 번 포스팅에서는 Unity에서 Niryo One 로봇으로 위치와 방향이 지정된 육면체를 집어 드는 픽 앤 플레이스(pick-and-place) 작업을 시연했습니다. 하지만 현실에서는 오브젝트의 정확한 위치를 선험적으로 파악하는 경우가 극히 드물기 때문에 이 솔루션은 효율적이지 않습니다. 새로운 오브젝트 포즈 추정 데모에서는 Unity Computer Vision Perception 패키지로 데이터를 수집하고 딥러닝 모델을 학습시켜 특정 오브젝트의 위치와 방향을 예측하는 방법을 볼 수 있습니다. 그런 다음 Unity에서 학습된 모델과 가상 UR3 로봇 팔을 통합하여 위치와 방향이 알려지지 않은 임의적인 오브젝트에 대해 완전한 픽 앤 플레이스 시스템을 시뮬레이션합니다.
현실의 로봇은 변화가 많은 환경에서 작동하는 경우가 많으며 이러한 환경에 반드시 적응해야 합니다. 이러한 상황에서 로봇은 관련 오브젝트를 인식하고 상호 작용해야 합니다. 오브젝트를 인식하고 상호 작용하려면 특정 좌표계를 기준으로 오브젝트의 위치와 방향(‘포즈’)을 파악해야 합니다. 초기의 포즈 추정 방식에서는 주로 기존의 컴퓨터 비전 기법과 커스텀 기준 마커가 사용되었습니다. 이 솔루션은 특정한 환경에서 작동하도록 설계되어서 환경이 변하거나 예상에서 벗어날 경우 오류가 발생하는 경우가 많았습니다. 기존 컴퓨터 비전의 한계로 인한 단점은 새롭게 떠오르는 유망한 딥러닝 기법에 의해 해소되고 있습니다. 새로운 기법은 수많은 예시로부터 학습하여 주어진 입력에 대해 정확한 출력을 예측할 수 있는 모델을 생성합니다.
이 프로젝트에서는 이미지와 실측 포즈 레이블을 사용하여 오브젝트의 포즈를 예측하는 모델을 학습시킵니다. 학습된 모델을 실행하면 이전에 본 적이 없는 이미지에서 오브젝트의 위치와 방향을 예측할 수 있습니다. 딥러닝 모델이 충분한 성능을 발휘하려면 보통 수만 장 이상의 이미지를 수집하고 레이블링해야 합니다. 현실에서 이러한 데이터를 수집하는 작업은 지루하고 비용이 많이 소요되며, 3D 오브젝트 위치 식별과 같은 일부 사례에서는 근본적으로 작업 자체가 어렵습니다. 설령 데이터를 수집하고 레이블링할 수 있더라도 편향이나 오류가 많거나, 지루하고 비용이 많이 소요될 수 있습니다. 필요한 데이터를 수집하지 못했거나 사용하려는 분야에 알맞은 데이터가 아직 존재하지 않는 상황에서, 강력한 머신러닝을 사용하려면 어떻게 해야 할까요?
Unity Computer Vision을 사용하면 머신러닝 데이터 요건을 효율적이고 효과적으로 충족하는 합성 데이터를 생성할 수 있습니다. 이번 사례에서는 Unity에서 자동으로 레이블링된 데이터를 생성하여 머신러닝 모델을 학습시키는 방법을 보여줍니다. 그런 다음 이 모델은 Unity를 통해 ROS(Robot Operating System)를 사용하는 시뮬레이션된 UR3 로봇 팔에 배포되어 위치와 방향이 알려지지 않은 육면체에 대한 픽 앤 플레이스를 수행합니다.
합성 데이터 생성

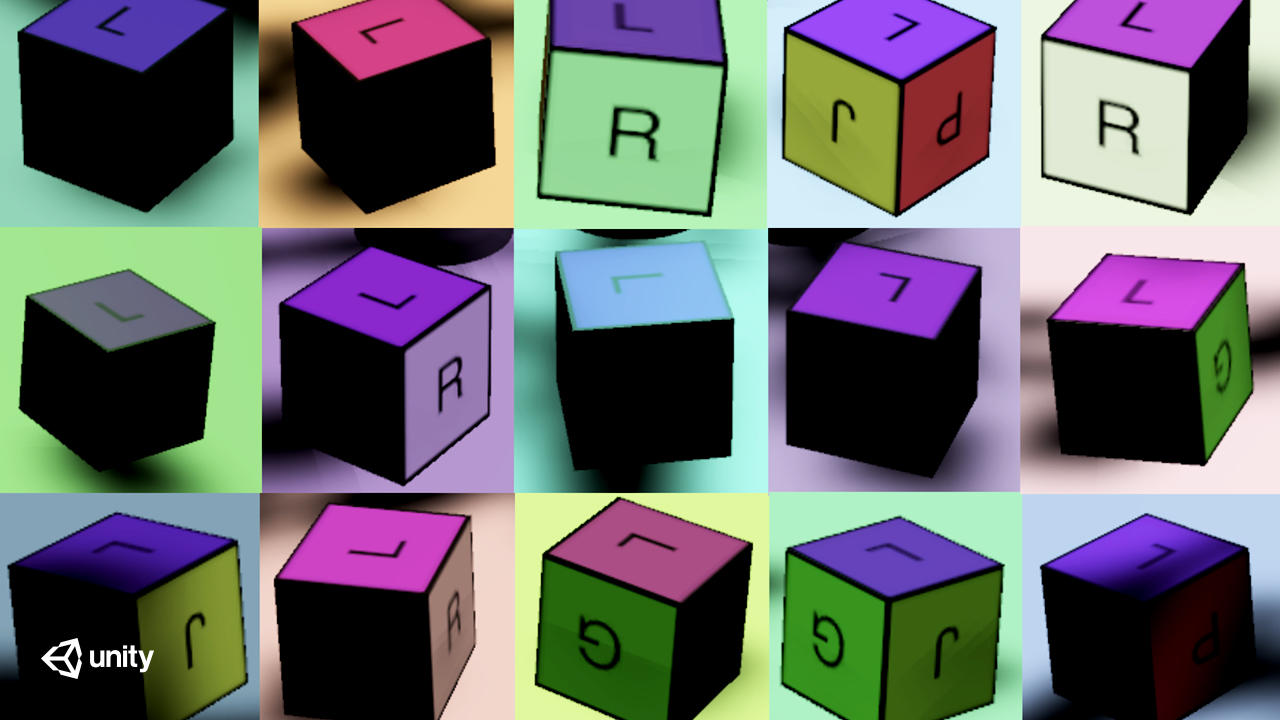
Unity와 같은 시뮬레이터는 합성 데이터를 생성하여 데이터 수집의 어려움을 해결하는 강력한 툴입니다. Unity Computer Vision을 사용하면 앞서 본 바와 같이 완벽하게 레이블링된 다양한 데이터를 최소한의 노력으로 대량 수집할 수 있습니다. 이 프로젝트에서는 포즈와 조명 조건이 다양한 육면체의 예시 이미지를 다량으로 수집합니다. 씬의 양상을 랜덤화하는 이 방법을 도메인 랜덤화1라고 합니다. 데이터가 다양할수록 딥러닝 모델은 더 강력해집니다.
실제 세계에서 육면체의 다양한 포즈에 대한 데이터를 수집하려면 육면체를 직접 움직이고 사진을 찍어야 합니다. 이 모델에서는 30,000장 이상의 이미지를 학습에 사용했는데, 이미지 한 장당 5초만 걸린다고 해도 이 데이터를 수집하는 데 걸리는 시간은 40시간이 넘습니다. 게다가 이 시간은 꼭 필요한 레이블링 과정을 고려하지 않은 시간입니다. 반면 Unity Computer Vision을 사용하면 단 몇 분 안에 30,000장의 학습 이미지와 별도의 검증용 이미지 3,000장을 올바른 레이블과 함께 생성할 수 있습니다. 이 예에서 카메라, 테이블, 로봇의 위치는 고정되어 있는 반면, 조명과 육면체의 위치와 방향은 캡처된 프레임마다 다릅니다. 레이블은 해당하는 JSON 파일에 저장되며, 이 파일에는 3D 포지션(x,y,z)과 쿼터니언(qx,qy,qz,qw)으로 위치와 방향이 설명되어 있습니다. 이 예에서는 육면체의 포즈와 환경 조명에만 변화를 주고 있지만, Unity Computer Vision에서는 씬의 다양한 요소를 손쉽게 추가로 랜덤화할 수 있습니다. 위치와 방향을 추정하기 위해 지도형 머신러닝 기법으로 데이터를 분석하고 학습된 모델을 생성합니다.
딥러닝을 활용하여 위치와 방향 예측

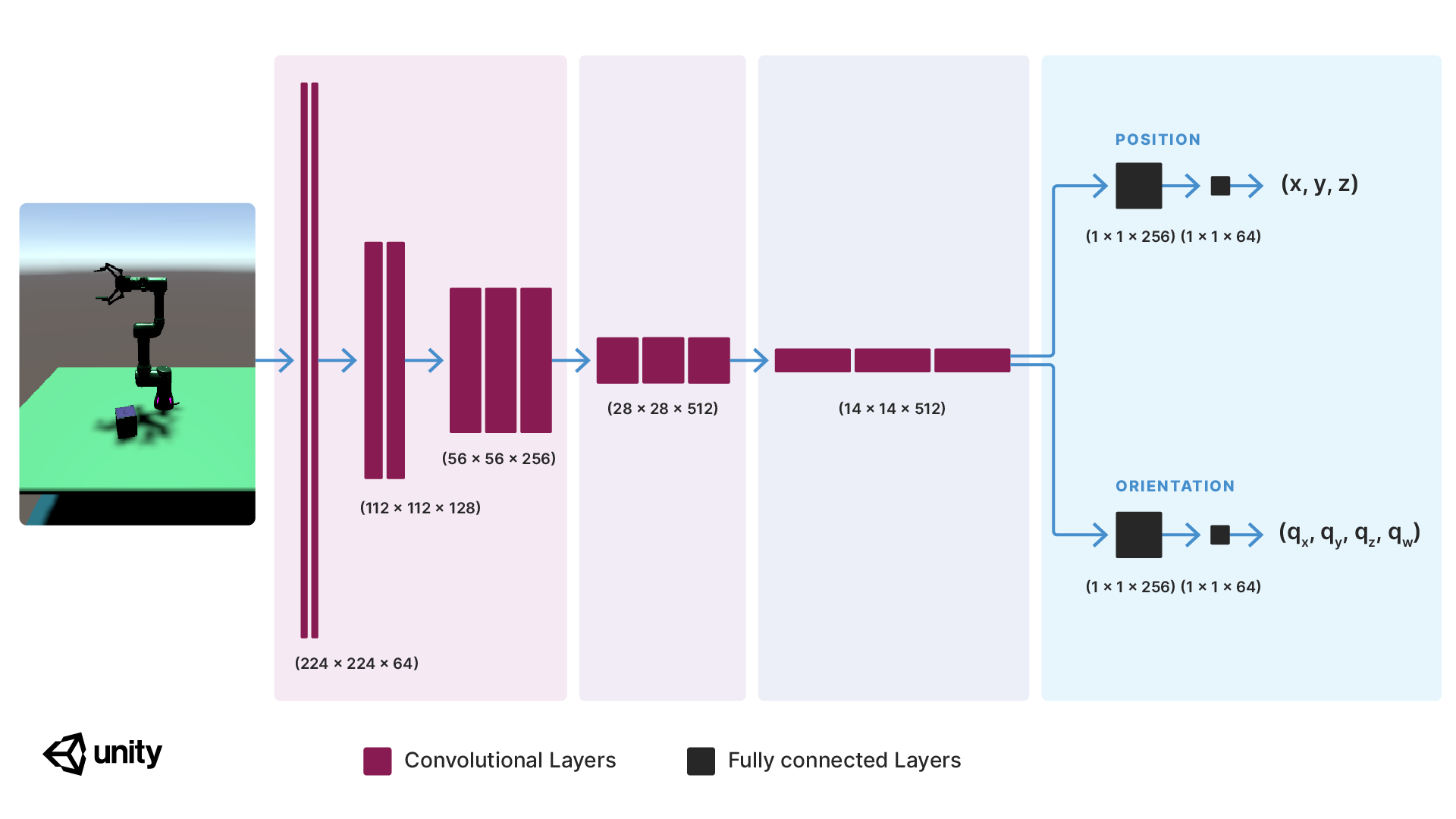
지도형 학습을 통해 모델은 입력과 해당 출력, 이미지, 그리고 이번 경우처럼 포즈 레이블 등을 학습하여 구체적인 결과를 예측하는 방법을 배웁니다. 몇 년 전, 한 연구 팀2에서는 오브젝트의 포지션을 예측할 수 있는 합성곱 신경망(CNN)을 발표했습니다. 우리는 육면체의 3D 포즈에 관심을 두고 있으므로 신경망의 결과에 육면체의 방향이 포함되도록 작업을 확장했습니다. 이 모델을 학습시키기 위해 최소 제곱 오차 또는 예측된 포즈와 실측된 포즈 사이의 L2 거리를 최소화합니다. 학습 후 모델은 육면체의 위치는 1cm, 방향은 2.8도(0.05 라디안) 이내로 예측했습니다. 이제 지금까지의 결과가 픽 앤 플레이스 작업을 수행할 수 있을 정도로 정확한지 살펴보겠습니다.
ROS 모션 계획
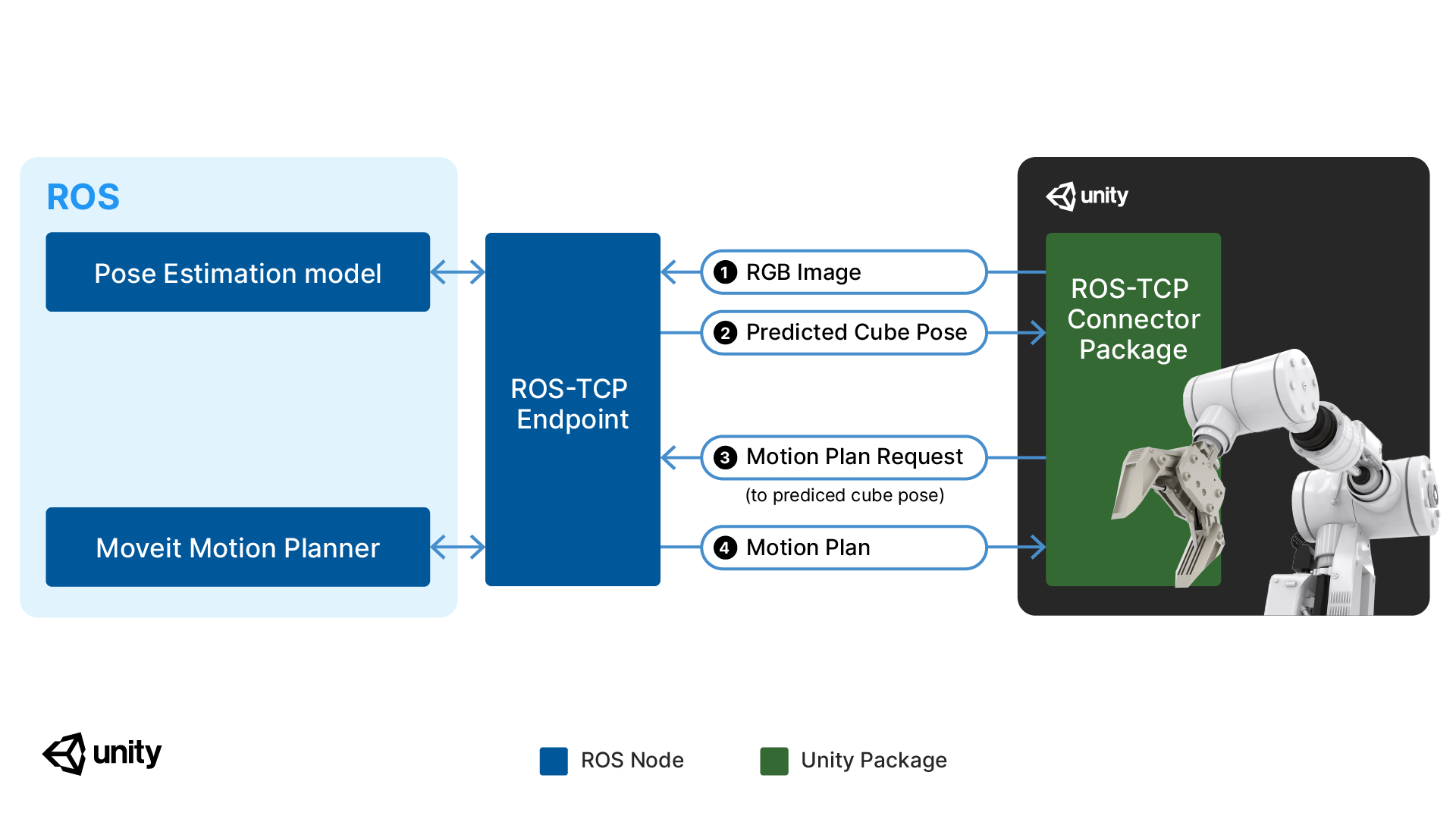
이 프로젝트에서 사용하는 로봇은 Robotiq 2F-140 그리퍼가 장착된 UR3 로봇 팔로, Unity Robotics URDF Importer 패키지를 사용하여 Unity 씬으로 불러왔습니다. 커뮤니케이션을 처리하기 위해 Unity Robotics ROS-TCP Connector 패키지가 사용되었으며 ROS MoveIt 패키지가 모션 계획 및 제어를 담당합니다.
이제 딥러닝 모델로 육면체의 위치와 방향을 정확하게 예측할 수 있게 되었으며, 이제 예측된 위치와 방향을 픽 앤 플레이스 작업의 대상 포즈로 사용할 수 있습니다. 앞서 픽 앤 플레이스 데모에서는 대상 오브젝트의 실측 위치와 방향을 사용했습니다. 여기에서 다른 점은 로봇이 육면체의 위치와 방향에 관한 사전 지식 없이 픽 앤 플레이스 작업을 수행하며 딥러닝 모델에서 예측된 위치와 방향만 가져온다는 점입니다. 이 과정은 아래 4가지 단계로 이루어져 있습니다.
- 대상 육면체의 이미지를 Unity에서 캡처합니다.
- 이미지가 학습된 딥러닝 모델로 전달되고, 예측된 위치와 방향이 출력됩니다.
- 예측된 위치와 방향이 Movelt 모션 플래너로 전송됩니다.
- 로봇이 육면체를 집어 올릴 수 있도록 ROS에서 Unity에 궤적을 반환합니다.
매 작업에서 육면체의 위치는 임의로 변경됩니다. 시뮬레이션에서는 육면체의 위치와 방향을 알고 있지만 실제 세계에서는 이 정보를 활용할 수 없습니다. 따라서 이 프로젝트를 실제 로봇에 적용하려면 센서 데이터만으로 육면체의 위치와 방향을 결정해야 합니다. 유니티의 포즈 추정 모델은 시뮬레이션 테스트를 진행한 결과 Unity에서 89%의 확률로 육면체를 안정적으로 집어들 수 있었습니다.
마무리
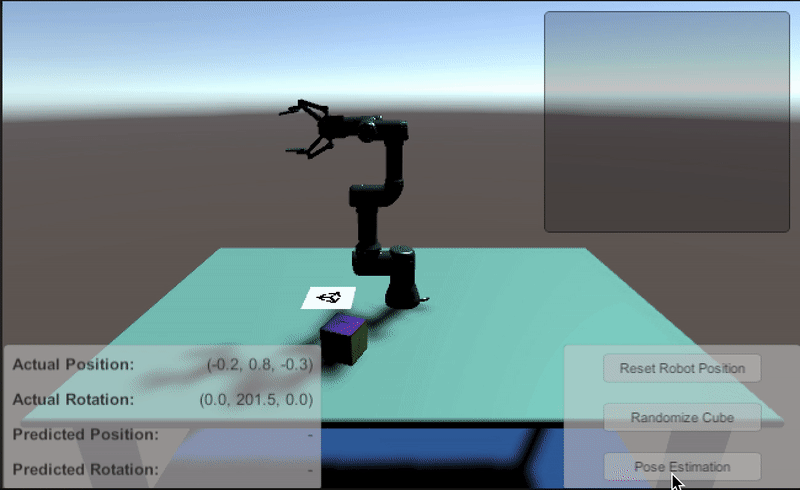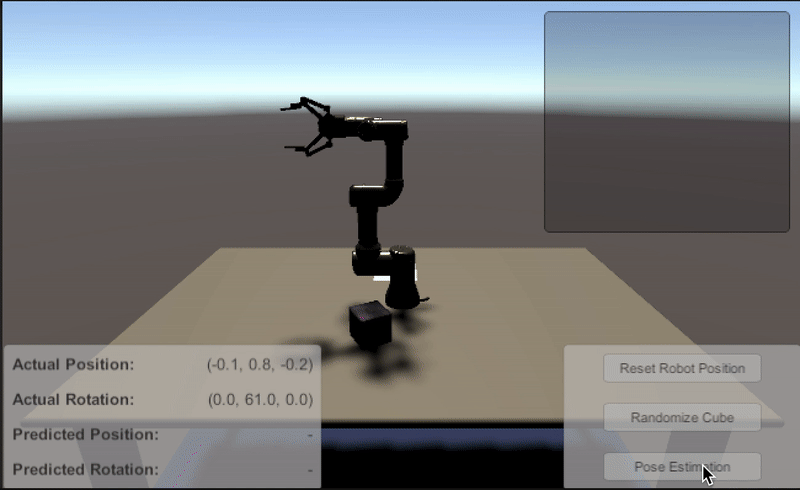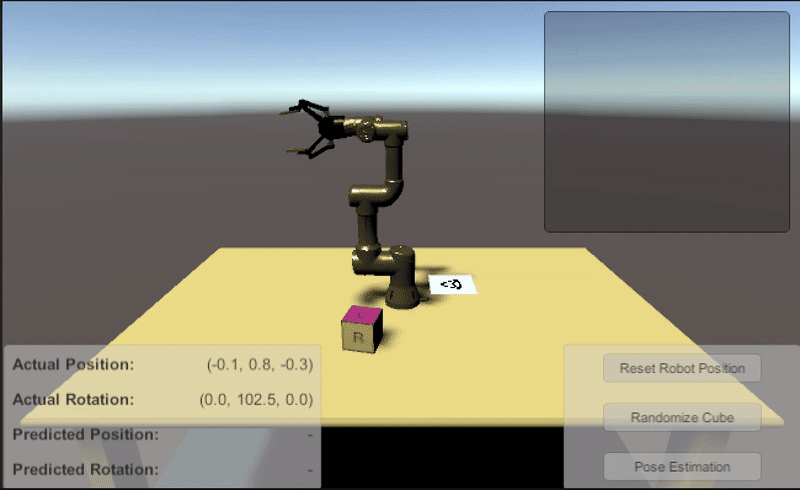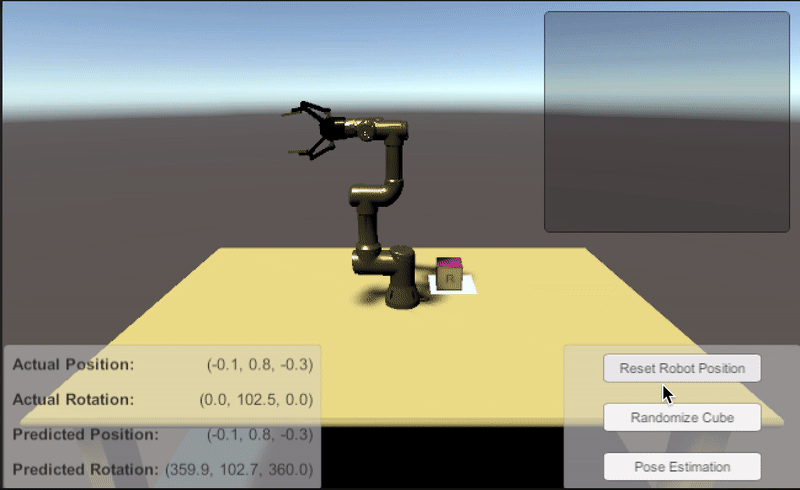
이번 오브젝트 포즈 추정 데모를 통해 Unity로 합성 데이터를 생성하고 딥러닝 모델을 학습시킨 후, ROS로 시뮬레이션된 로봇을 제어하여 문제를 해결하는 과정을 확인할 수 있었습니다. 여기에서는 Unity Computer Vision 툴을 사용하여 레이블링된 합성 학습 데이터를 만들고 단순한 딥러닝 모델을 학습시켜 육면체의 위치와 방향을 예측했습니다. 데모에서 제공하는 튜토리얼을 통해 더 많은 랜더마이저(randomizer)를 적용하고 더 복잡한 씬을 만들어 프로젝트를 확장할 수도 있습니다. 학습된 모델을 사용하여 육면체의 위치와 방향을 예측하는 ROS 추론 노드는 Unity Robotics 툴을 통해 사용했습니다. 이 툴과 다른 여러 툴을 이용하면 솔루션을 탐색, 테스트, 개발하고 로컬에 배포할 수 있습니다. 솔루션을 확장하려는 경우 Unity Simulation을 이용하면 실제로 시뮬레이션하는 것보다 시간과 비용을 아낄 수 있습니다.
Unity Computer Vision과 Unity Robotics 툴은 모두 무료로 사용할 수 있습니다. 오브젝트 포즈 추정 데모에서 지금 바로 사용해 보세요.
프로젝트 확장
이제 위치와 방향이 알려지지 않은 오브젝트를 집어들 수 있게 되었으니 어떻게 확장할 수 있을지 상상해 보세요. 오브젝트 앞에 장애물이 있다면 어떻게 될까요? 혹은 오브젝트가 씬에 여러 개 있는 경우는 어떨까요? 다양한 상황에 어떻게 대처할 수 있을지를 생각해 보고, 다음 포스팅도 기대해 주시기 바랍니다.
더 자세히 알아보고 싶으시다면 로보틱스 또는 컴퓨터 비전 분야에서 유니티가 진행 중인 작업에 대한 뉴스레터를 신청해 보세요.
Unity Robotics GitHub에서도 더 많은 로보틱스 프로젝트를 찾아볼 수 있습니다.
더 많은 컴퓨터 비전 프로젝트를 보려면 Unity Computer Vision 페이지를 방문하세요.
유니티 로보틱스 팀에게 질문 또는 의견을 제안하고 싶다면 unity-robotics@unity3d.com로 이메일 보내주세요.
출처
- J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, P. Abbeel, “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World” arXiv:1703.06907, 2017
- J. Tobin, W. Zaremba, and P. Abbeel, “Domain randomization and generative models for robotic grasping,” arXiv preprint arXiv:1710.06425, 2017
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies