The Great Incident Bash of 2015







It’s been 1.5 years since we last did an incident bash, so time was ripe for executing another in order to get some fresh data. Enter the Great Incident Bash of 2015.
Just to make sure we have the terms in place: An incident is when a user sends us a report through the bugreporter. An incident is turned into a bug when one of our testers has successfully reproduced the incident as a bug.
An incident bash is a period of time where we mark up a random sample of bugs within a given time period. In this case, we took 28 days of incidents that came in on version 5.0.1f1. We looked at 5.0.1f1 because it is the first release to roll up the initial patches after 5.0. We get a majority of incidents a month or two after the release, so this was a good time to look at it. Our sample had a total of 2058 incidents of which we randomly marked up 25%, leading us to fully investigate 491 cases.
Fully investigating a case means that we try to reproduce every case, respond to the user if we miss information, follow up on every response and try to get to the bottom of each case. This is immensely time consuming, but doing it on a random sample gives us a lot of information.
Going through 491 incidents, we managed to turn 73 into a bug:

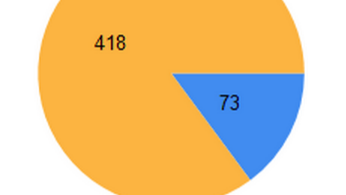
That’s a total of 14.86% of the entire population. Compared to the previous value of 6.83%, this is a lot more valid bugs, but it is also very low compared to the effort of digging them out. In other words, 85% of all incidents we get are in fact not bugs or duplicates of known issues. Having to wade through 7 bugs to actually find something real is an immense waste of time, so normally we don’t do that.
What we do is prioritize incidents according to a rating system. The rating takes into account the description, attached projects, images and files. It ranges from 0 (crash, profanity, no added information) to 5 (project attached and a solid description). We also handle incidents from our enterprise support customers first, because we have direct relations with them already. As such, we take incidents in the following order:
Enterprise customers -> Pro Rating 5 -> Rating 5 -> Pro Rating 4 -> Rating 4 -> etc.
Because of the incident bash, we now have the data to check whether this system is working.
The overview of the ratings on the incidents we started with shows that 4 and 5 are the smallest portion of the total pool.

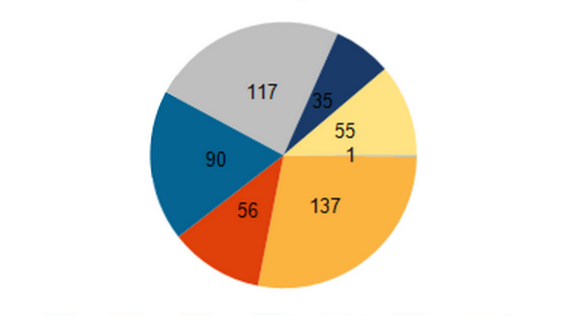
We can see that 55 Rating 5 and 35 Rating 4 incidents out of the total 491 is not a lot. The one incident without a rating got through by mistake, but we included it for completeness sake.
Looking at the spread of the bugs according to the rating they had, we see the following picture:

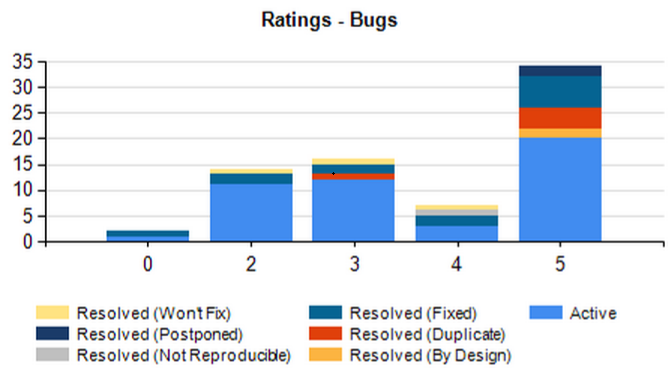
As expected, the vast majority of actual bugs were those with a rating of 5. And that’s out of the smallest pool of incidents.
The rating 0 incidents that do turn into bugs are most likely crashes that we have automatically identified through our crash analysis tool. We will blog about that later in the year. For now, please make sure you send all crash reports to us, even if you don’t add information. We can use the data for processing automatically.
| Rating | Chance of Bug |
| 0 | 1% |
| 1 | 0% |
| 2 | 16% |
| 3 | 14% |
| 4 | 20% |
| 5 | 62% |
This table really tells the story of why we are so insistent on getting a repro project attached and get a good description as well. Rating 4 is a solid description, but no attachment, while 5 is both. The difference is a 3 times larger chance of reproducing the issue and ultimately filing a bug that can be fixed.
It also tells the story of why we prioritize rating 5 so high. We are hunting bugs, as many as we can in the time we have available. That means prioritizing the effort on where the biggest chance of finding a bug is present. We will never be able to handle and respond to all incidents, there are simply too many incoming. To date, we have gotten 4.510 incidents reported on just version 5.0.1f1, of which only 10.7% percent have rating 5.
There are other things we are working on to change the flow of incidents. Coming in 5.3, we will integrate an automated search in the bug reporter itself. This will attempt to present possible solutions to a user as they are filling out the form, which will hopefully allow them to solve the problem much faster than having a turnaround with our team.
Further down the road, we will integrate crash lookups with our internal crash analysis tools, so a crash will automatically be able to tell the user whether it is a known problem, if there is a patch that solves it or if this is a new crash and we need more information. There are many other ways we can improve the bug reporter and we’re continuously working on it.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies