Bug Reports, Incidents and some bashing






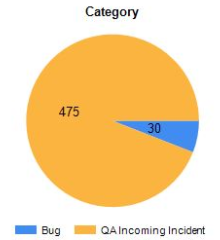
When a bug report is sent to us, it becomes a “QA Incoming Incident” (see https://blog.unity.com/community/i-numbers) that QA will have to process. At least we process as many as we can, because we receive A LOT of them (~1100 per week). We have been unable to even respond to a fraction of them, because we always prioritize our latest version (beta and alpha) higher. We do that because the chance of getting those bugs fixed is higher and thus more valuable to the product. We really want to respond to everyone, but it has to make sense for us and to figure out if it really does, we had to get some data.
We wanted answers to a few questions:
- How many bugs can we find in those reports?
- How good is our rating system? (brief explanation below)
- How much time should we invest in them?
- How much information can we get by asking users for more info on a report?
- Can we somehow improve the workflow for everyone, including users?
The rating system
The rating system is a way for us to categorize incidents based on how good the report is, i.e., how likely is it to be reproducible and an actual bug in the system. To do this, we look at how much information is on the bug in the form of attachments and how much text has been entered in the description.
- 0: Very little or no description. No attached files. User selected “First time” or “Sometimes”.
- 1: Very little or no description. No attached files. User selected “Always”
- 2: A small amount of description.
- 3: An attachment is present (typically a project), but little to no description.
- 4: A good amount of description is present, but no attachment.
- 5: Good description and attachments present.
It is a very simple and crude rating, so it was interesting to see some data on whether it really worked.
Enter the Incident Bash
We had at the time, Tuesday October 15th, ~2000 active QA Incoming Incidents on version 4.2.1f4. Of these I randomly selected 25%, resulting in 505 reports we wanted to process. All hands on deck for one day. 38 people doing whatever we could to get this to 0 in one day. And we made it.

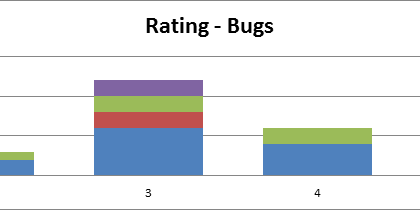
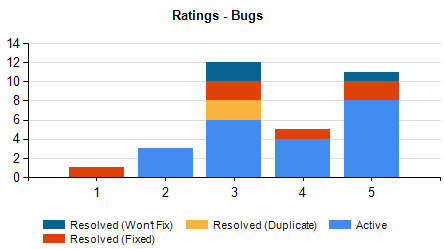
The initial 505 incidents were spread on these ratings:
More than 60% were in the first three ratings, meaning little to no input from the user. Only 60 had a good description.
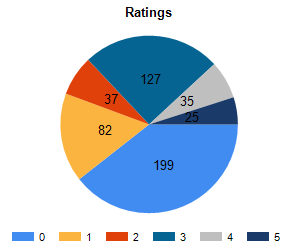
After the incident bash, we looked at the number of bugs we had reproduced:
So after the initial processing we discovered 5.94% reproducible bugs in the pile of 505 incidents.
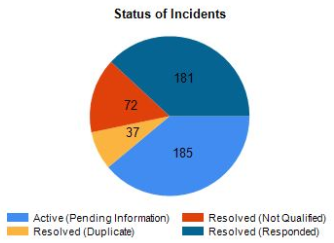
Of the incidents we processed, we replied to the user on 185 of them asking for more information about the bug; 37 were duplicates of existing bugs; 72 did not contain enough info to be reproducible nor had an email been sent to ask for more information, and finally, we responded to the user in 181 cases explaining that the incident was not caused by a bug, but by something else going wrong.
Of the 185 cases where we asked for more info we received an answer from 57 of the users one week later. The total bug-count had risen by 2. The final bug count total is:
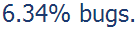
That number is not exactly awesome. Let’s see how the rating distribution was:
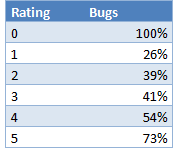
Combine that with the total number of cases in each rating and we get the following probabilities of an incident turning into a bug based on the rating:

So the answer to the question of whether our rating system works is a big yes!
Let’s compare this to our alpha and beta users. Remember how I said we focus a lot more energy on those reports?
As you see, the probability of getting a bug out of a report from our beta users is higher. It makes sense for us to focus a lot more energy on those reports than on the reports from the publicly released versions. Also, more than 80% of all bugs in the alpha/beta groups are rated 3-5.
The distribution of the bugs we found was without large spikes. That is a good sign of not having great holes in our system:
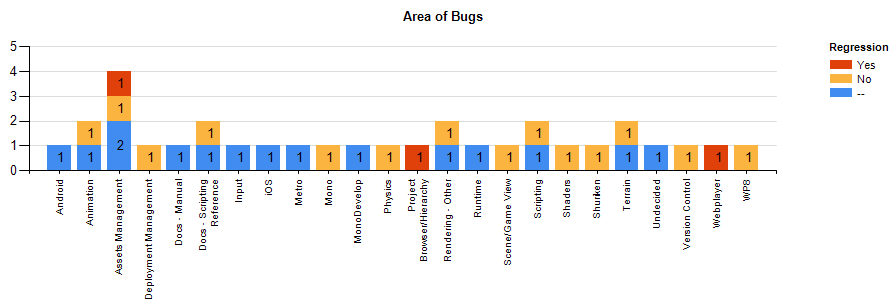
We had 3 regressions in that pack of reports, which is a nice find, but not scary to us.
Conclusions
First of all I have a plea: Dear user, if you want to increase the chance of a bug you report being reproduced and fixed, give us a good description of the problem and attach a project or video to the report. Based on the small experiment we did, providing such information results in a higher chance that we will be able to reproduce the bug (2-44x higher, depending on which extremes you compare). Reproducing the bug is the first step to even considering fixing it.
Next, we have a well functioning rating system. We want to incorporate this better in the future versions of the bug reporter.
Finally, I want to say one thing loud and clear: If you get a crash in the editor, press “Send Error Report” even if you have no clue what happened! We have a separate system for automated analysis of crash reports, which we use for finding bugs from pure statistics on the crashes happening. That system is worthy of a separate blog post, so stay tuned for that.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies