2020 AI@Unity interns shoutout





Each summer, interns join AI@Unity to develop highly impactful technology that forwards our mission to empower Unity developers with Artificial Intelligence and Machine Learning tools and services. This past summer was no different, and the AI@Unity group was delighted to have 24 fantastic interns. This post will highlight the seven research and engineering interns from the ML-Agents and Game Simulation teams: Yanchao Sun, Scott Jordan, PSankalp Patro, Aryan Mann, Christina Guan, Emma Park and Chingiz Mardanov. Read on to find out more about their experiences and achievements interning at Unity.
During the summer of 2020, we had a total of 24 interns in the AI@Unity organization, seven of whose projects will be overviewed here. What was particularly remarkable is that all seven projects were experimental in nature which helped us push the boundaries of our products and services. All seven projects listed below will eventually make their way back into the core product in the coming months as key features that will delight our users.
The seven interns whose projects are overviewed in this blog post were part of the ML-Agents and Game Simulation teams:
- The ML-Agents team is an applied research team that develops and maintains the ML-Agents Toolkit, an open-source project. The ML-Agents Toolkit enables Unity games and simulations to serve as training environments for machine learning algorithms. Developers use ML-Agents to train character behaviors or game AIs with deep reinforcement learning (RL) or imitation learning (IL). This avoids the tediousness of traditional hand-crafted or hard-coded methods. Aside from the GitHub documentation, you can learn more about ML-Agents in this blog post and research paper.
- The Game Simulation team is a product team whose mission is to enable game developers to test and balance their game by running multiple playthroughs in parallel in the cloud. Game Simulation launched earlier this year, and you can learn more by checking out the case studies we published with our partners iLLOGIKA and Furyion.
As Unity grows, our internship program grows as well. In 2021, the size of the AI@Unity internship program will increase to 28 positions. Additionally, we are hiring in more locations, including Orlando, San Francisco, Copenhagen, Vancouver, and Vilnius, for positions ranging from software development to machine learning research. If you are interested in our 2021 internship program, please apply here (and watch this link as we’ll post additional internship roles in the coming weeks). And now, please enjoy the many and varied projects of our talented interns from summer 2020!
Yanchao Sun (ML-Agents): Transfer learning
In most cases, a behavior learned with RL will work well in the environment in which it's been trained but will fail significantly in a similar but different environment. As a result, a simple tweak to the game’s dynamics requires that we discard the previous policy and train everything from scratch. During the summer of 2020, I developed a novel transfer learning algorithm tailored specifically to the incremental process of game development.
Problem: Game development is incremental; RL is not
Game development is incremental – a game usually starts from a simple prototype and gradually grows in complexity. However, RL is not incremental, and training a policy is time-consuming. Using ML-Agents in game development could become expensive, as a developer may need to wait several hours or even days to see how an RL agent responds to a modification. Although some approaches can make the policy more general in the training process, e.g., domain randomization, they only apply to game variations that can be specified before training and cannot adapt to arbitrary future game evolutions.
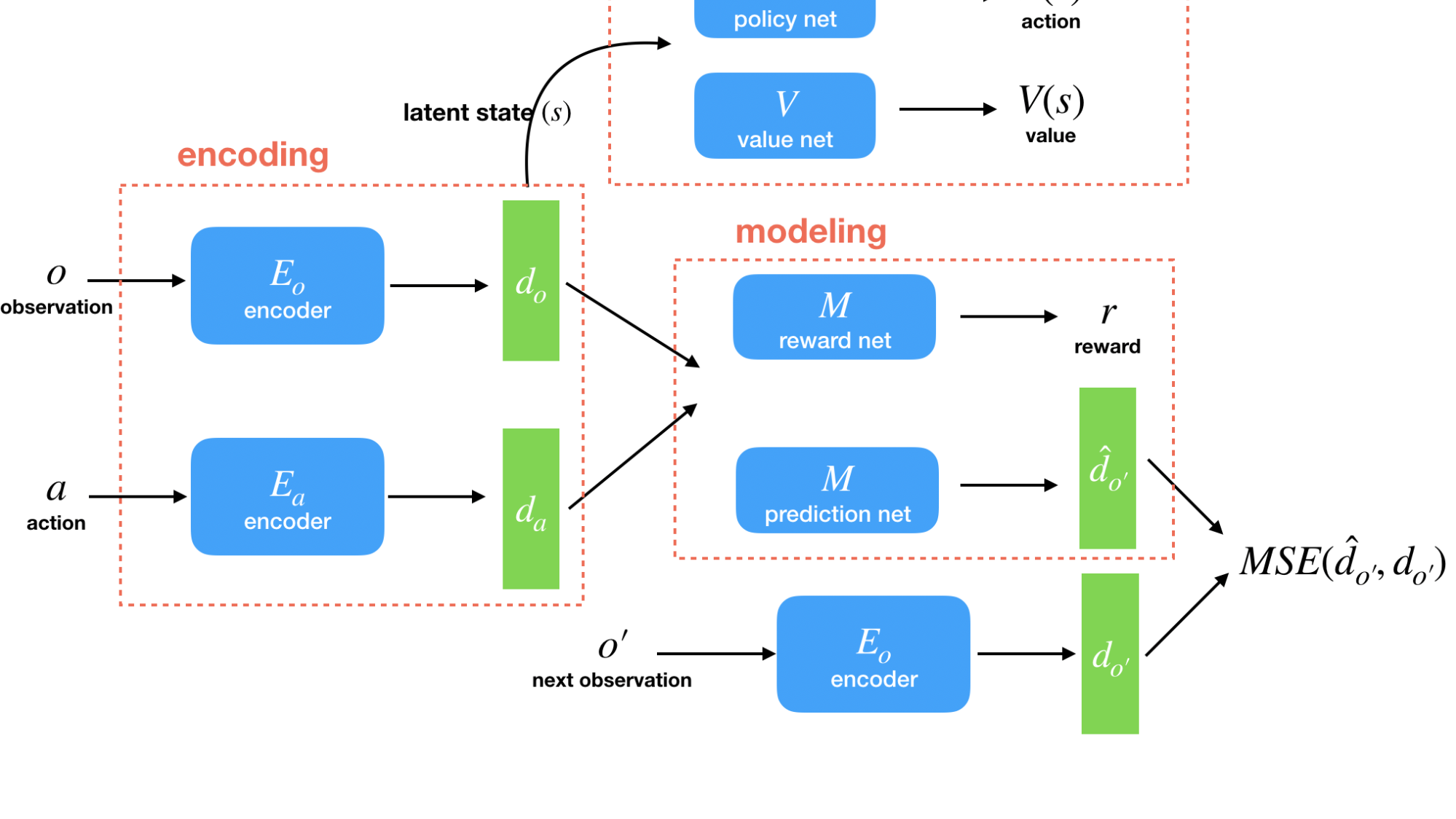
Solution: Disentangle representation and prediction
Intuitively, a small tweak to the dynamics of a game or how the agent interacts with it leaves the rest of the game largely unchanged. For example, giving the agent a better sensor with higher-resolution changes how it observes the world but does not change how the world works. Following this insight, we developed a novel transfer learning approach that extracts underlying environment features that can be transferred to the next iteration of the environment. A transfer learning algorithm uses knowledge gained while solving one problem to facilitate learning a different but related problem. Transferring knowledge of the unchanged aspects of the problem can significantly improve learning speeds in the new domain. Our work proposes a model that separates the representations of the agent’s observations and the environment’s dynamics. So when the observation space changes but dynamics do not, we will reload and fix the dynamics representation. Similarly, when dynamics change but observation space does not change, we reload and fix the encoders. In both scenarios, the transferred pieces act as regularizers for the other portions of the model.

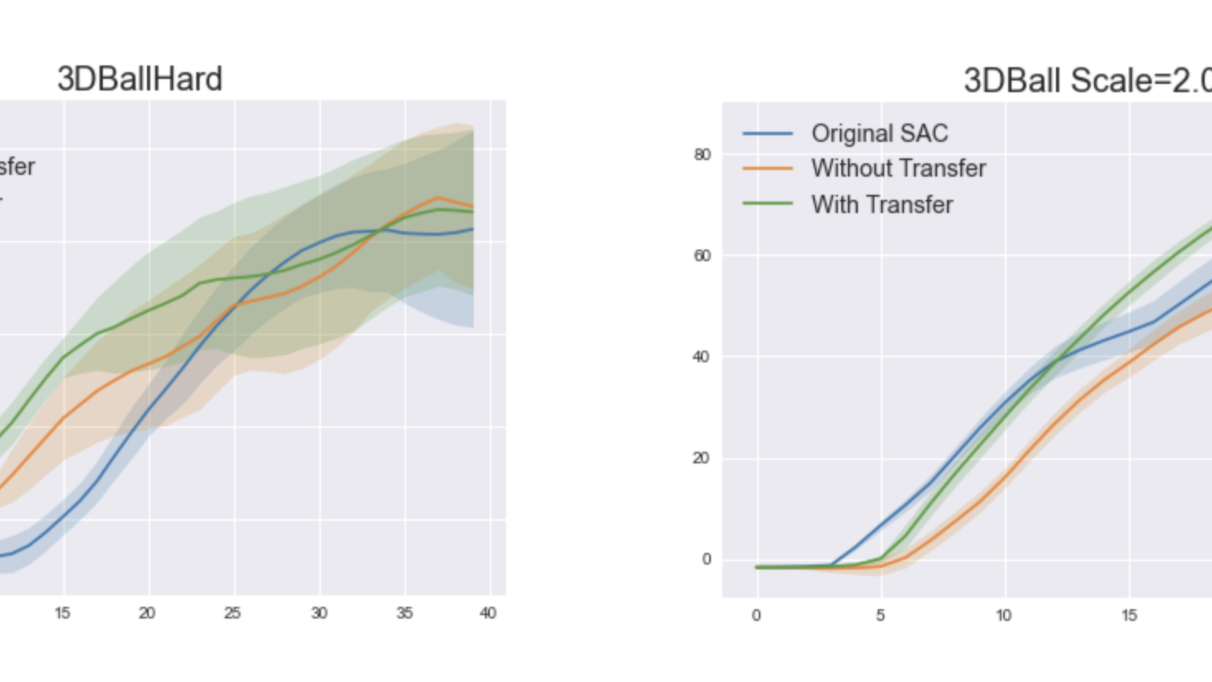
To test our method (to be made available in a future version of ML-Agents), we selected the 3DBall and 3DBallHard environments in the ML-Agents Toolkit. These environments have the same dynamics but different observation spaces. We also added an extra penalty on the agent’s action magnitudes. The goal of the agent is to balance the ball with minimal energy expenditure. To test the change of observation, we first trained a model-based policy on 3DBall and then transferred the modeling part to the learning of 3DBallHard. Compared with the standard Soft Actor-Critic algorithm and a single-task model-based learner, the learning-with-transfer method gets the highest reward. We also evaluated the dynamics-change case by increasing the size of the ball. The results show that transfer learning beats the single task learners and is more stable!

Scott Jordan (ML-Agents): Task parameterization and active learning
In an RL setting, a developer specifies the desired behavior by defining a reward function, a scalar function that returns a value indicating a particular outcome’s desirability. Specifying a reward function can be challenging and often needs to be adjusted to capture the developer’s intentions. This trial-and-error workflow can become extremely expensive due to the data needs of RL. In this internship, I looked at ways to improve upon this process using task parameterization and active learning algorithms.
Problem: Reward functions require tuning
Consider an agent tasked with navigating to a given location. The agent will likely learn to run to the target location as fast as possible. For a developer, this learned behavior could be undesirable and a game scenario it may be too difficult for a human to compete against. So, the developer modifies the reward function to penalize the agent for moving too fast. Then, the developer retrains the agent using the new reward function and observes the learned behavior. This process repeats until the game developer is satisfied. This iterative process can become prohibitively costly as the agent tasks become more complex.
Solution: Learn to solve a distribution over tasks
To alleviate the need to specify exactly the correct objective, we use a parameterized task definition of the agent’s objective function. In this setting, the agent’s task has some parameters that are adjustable or can be sampled. To use the example from the previous paragraph, the agent’s task would be to move to the target location, and the speed at which the agent does this is a parameter. So, instead of specifying a single behavior to learn, the developer instead specifies a range of behaviors, e.g., to move toward a target location but with varying speed. Then, after training, the task parameters can be adjusted to best reflect the desired behavior. The ML-Agents Toolkit currently includes an instance of the Walker agent whose task it is to run with variable speed. Additionally, we also created a variable speed version of Puppo that tells him how quick to run while playing fetch and a head height parameter which trains Puppo to hop around on his hind legs.
Parameterized tasks are useful for learning multiple behaviors, but the question of which parameterizations we should use in training is nontrivial. The naive approach is to randomly sample parameterizations, but this can be inefficient for a number of reasons. We opt for the smarter alternative of active learning (Da Silva et al. 2014). Active learning is a technique that learns which parameterizations to train on to maximize the agent’s expected improvement during training. This allows the agent to learn all task parameterizations with fewer samples. For the previous example of Puppo with head height and variable speed parameters, we compare Active Learning with Uniform Random sampling of task parameterizations below.


PSankalp Patro (ML-Agents): Tracking model outputs
Reinforcement learning requires heavy compute resources, which are often far more than an average user possesses on their laptop or desktop. To make training easier for our users, the ML-Agents team is currently developing ML-Agents Cloud, an experimental cloud training service for ML-Agents (announced in our Release 1 blog post).
ML-Agents Cloud offers several advantages to users. Developers can now run multiple experiments in parallel rather than a single experiment on their local computer. With superior computing capabilities, training time is reduced, and complex environments can be trained in less time. ML-Agents Cloud also circumvents the installation and setup of machine learning libraries and versioning (such as Tensorflow and PyTorch) required to run ML-Agents training.
Problem: No tracking nor serving of models generated by experiments
Prior to this internship, ML-Agents Cloud did not provide options for users to interact with the models generated from their experiments. Since reinforcement learning experiments can take hours, it is natural to produce intermediate model checkpoints in addition to the final model. Checkpoint models can be used to chart the model’s learning progress or to resume training from a given point. Since the trained models are the most important output from ML-Agents, we wanted to provide a good way for users to view and track their models.
Solution: Build a back end for model tracking and serving
To solve this problem, I decided to build a back end for tracking and serving model files trained within ML-Agents Cloud. This involved:
- File Tracking: I collected metadata about the models generated, such as the training step at which the model was generated and the recent average reward values for the agents. At the end of training, the model metadata is stored in a database and associated with the experiment so that users could easily sort and filter their model outputs.
- API and CLI: Next, I created the interface for users to interact with their models stored in the cloud by extending the ML-Agents Cloud API and command-line interface.
- Prototyping ML-Agents Cloud with the Unity Editor: Using the components mentioned earlier, I built a prototype to integrate ML-Agents Cloud with the Unity Editor. This component’s goal was to present a potential end-to-end integration between ML-Agents Cloud and the Unity Editor to make the Editor a one-stop-shop for RL training. Further, this provided a proof of concept for how seamless cloud training could become with ML-Agents Cloud, eliminating nearly all configuration overhead.
Aryan Mann (Game Simulation): Game simulation and procedural generation
One of the mechanisms used to create challenging, exciting and diverse gameplay is to leverage procedural content generation. At the core of a procedural content generation system is a procedural generator, a function that uses a random seed to generate a set of outputs. For some configuration of inputs, the set of all worlds produced from all seeds is that configuration’s generative space. When we change the configuration by modifying one or more inputs, a different set of worlds is produced and, consequently, a different generative space.
Problem: QA on procedural content is challenging
One of the major difficulties with procedural functions is quality assurance. The downside of generating a large amount of content is that playtesting becomes a tremendously difficult task. There are techniques to evaluate the quality or balance of generated content, but most of these current techniques are agent-independent. This means they measure concrete items in the level, like the size of a level, the number of enemies, or the number of doors. This method is limited and prevents us from drawing any conclusion on how players will interact with a given seed.
Solution: Testing with smart agents that play your game
Instead, what we want to achieve is full agent-interdependence. This requires having an agent that can play any level in the expressive range of your procedural generator. With that agent, the balance or quality of a level can be measured. Measurements like completion time, difficulty, or infeasibility are made possible through the agent’s play. This changes game balancing from a mathematical model to running your game as a black box function. To measure this function, we can have droves of simulated players explore larger and more representative subsets of the generated content through a tool like Unity Game Simulation. To prove this theory we trained a simple bot to play in the Obstacle Tower Environment from ML-Agents. This is a procedurally generated tower with increasing difficulty that served as a benchmark in a deep reinforcement learning challenge run last year.
Obstacle Tower: A case study

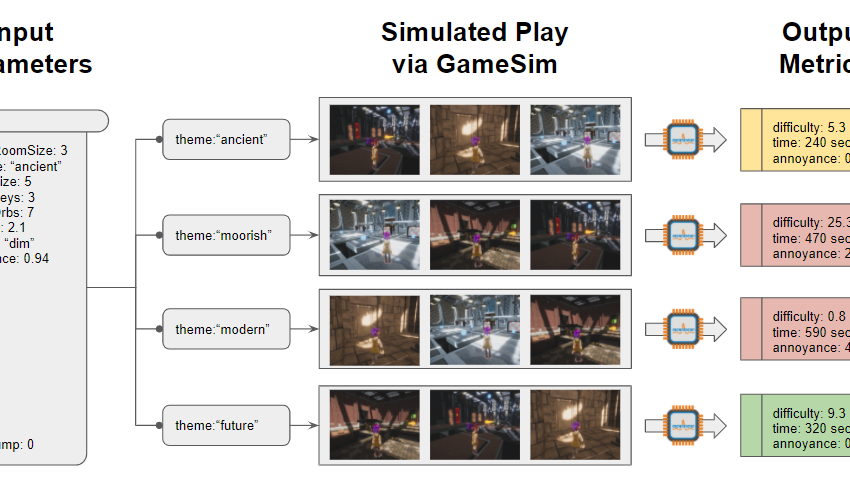
The primary question to explore was whether it was possible to pinpoint the types and ranges of input parameters that lead to roadblocks while training our agent, thus balancing the procedurally generated tower for our agent. Obstacle Tower has five different themes that dictate the style and type of objects that compose a level, such as pillars, doors, or the floor. Using Unity Game Simulation, we ran simulations on a common set of levels (seeds) across five different visual themes and then cross-compared the generated metrics. These included maximum performance and a hotspot distribution of the agent’s position. The modern theme had worse performance and an odd hotspot in front of the door for the level. We identified a roadblock where the arrow symbol on the door was incorrectly flipped, which had blocked the agent’s progress. Measuring content based on synthetic data is a challenging proposition, but one we feel is very worthwhile. Stay tuned for more blog posts about sample environments and techniques for measuring content with Game Simulation.
Christina Guan (Game Simulation): Simple bots for game testing
One of the steps in using Game Simulation is to create a bot that can play through the game or level that you wish to test. There are a number of tools that exist for creating game AI’s which naturally extend to creating bots that can play through a game.
Problem: Bot Creation
In this internship project, I wanted to experiment with Unity tools for creating simple bots that developers can use to test their games on Game Simulation. This would provide a Unity-native solution that works seamlessly with Unity’s new Input System. The Input System is designed to be far more extensible and customizable than the classic input system. It allows users to bind specific actions quickly and easily to multiple controller types without needing to make major changes to the script, making it easier for games to support a variety of platforms and devices. It also has the added benefits of being easily driven from code and handled by events that can be traced and handled, giving developers the tools to build simple but useful bots for their games.
Solution: Input system bots
Over the course of my internship, I built two different bots that both used the input system package: a “monkey” and a “replay” bot. These bots were designed with QA and bug testing in mind. The monkeybot can continuously test large varieties of input combinations at random, useful for input edge case testing. The replay bot would be most useful for recording and replaying different QA tests, allowing a human tester to focus on other tasks rather than the same repetitive set of tests. Furthermore, both bots are architected to not require specific game code dependencies and are structured in a way that developers can add or modify parts as needed.
The monkey bot enables developers to test input controls by driving the input system through code. Developers can specify the inputs they want to test, and the monkey bot will generate a random sequence of those inputs. The monkey bot also allows developers to test one input or multiple inputs simultaneously.
The “replay” bot enables developers to record and replay sequences of inputs. It catches event traces from the input system as inputs are triggered and matches those events to inputs that affect the game. The bot then creates a list of inputs and timestamps that are stored in a JSON object. JSON objects can be modified or replayed as is through the bot. Currently, this bot is only compatible with the keyboard input device.
For the purpose of my summer internship, these bots were useful to explore the capabilities of the new input system and allow myself a deeper understanding of its capabilities. On top of that, I built a proof of concept for how these bots can be used as an off-the-shelf solution to help ease the testing burden on game teams.
Emma Park (Game Simulation): Optimize games with the Virtual Player Manager
Game testing plays a crucial role in improving game quality during the game development process. But this requires repetitive and time-consuming manual work; the developer needs to maintain separate code branches and change their code architecture after each test with different players. To address this issue, my summer intern project – the Virtual Player Manager – aims to help game developers establish workflows that can provide valuable information to tune their games. “Virtual players” in this context refer to any kind of bot or automated player script that can be used to help test and optimize your game. The Virtual Player Manager consists of two main features: management of virtual players and simulation on different players.
Problem: Managing virtual players in your game is hard
Currently, there is no structured way for game developers to manage virtual players in a Unity project. They spend a significant amount of time organizing their scripts into different categories for easier management and game playing to measure the performance between the players. This process makes it difficult to run multiple tests with virtual players.
Solution: Provide an interface for game developers to manage and run simulations with their virtual players
The Virtual Player Manager will provide a clean and structured way to manage all the player scripts and run multiple simulations with virtual players.
Unity Editor Virtual Player Manager UI component
In the Unity Editor, Virtual Player Manager provides a UI component that enables game developers to observe the behavior of virtual players by easily switching between different virtual players.
As you can see in the video below, all you need to do is create your own player scripts and drag all the scripts to the Virtual Player Manager. You don’t need to maintain separate code branches or make adjustments after each playtest.

Virtual Player Manager UI in Game Simulation Dashboard
In the Game Simulation dashboard, you can manage multiple iterations of your player bots while simulating various changes. Here, you can leverage Unity Remote Config to save and get “virtual player bots settings” from the cloud for each simulation.
After your simulation is complete, you can download a Player Log to analyze simulation results and evaluate performance among players.
Chingiz Mardanov (Game Simulation): Automatic in-game parameter tuning exploration
As part of the Unity Game Simulation team, I helped enable automated testing and game balancing. Our service currently allows developers to select values for tunable in-game parameters and then executes all the possible combinations of them in the cloud, while tracking the produced output metrics.
Problem: Finding optimal parameters for desired outcomes is challenging
A potential next step in developing the Game Simulation service that we are exploring is helping developers by suggesting parameter combinations that would achieve the game behavior they want. For example, suppose developers would like to ensure that a level never takes longer than three minutes to complete. What should we set the player’s move speed to? How many enemies should we include in the level to accomplish this time goal?
Solution: Black-box optimization
To answer such questions efficiently, we can use black-box optimization. The main goal of the black-box optimizer is to minimize or maximize a function with the fewest evaluations possible. If we think of our game as a function that maps input parameter combinations to output metrics we can score a game configuration based on how far it is from desired metrics and supply this information to the optimizer. This allows us to search for optimal parameter combinations much faster than by just trying all possibilities. There are many frameworks available that provide a convenient way to use black-box optimization algorithms, but for this internship, I primarily used Google Vizier.
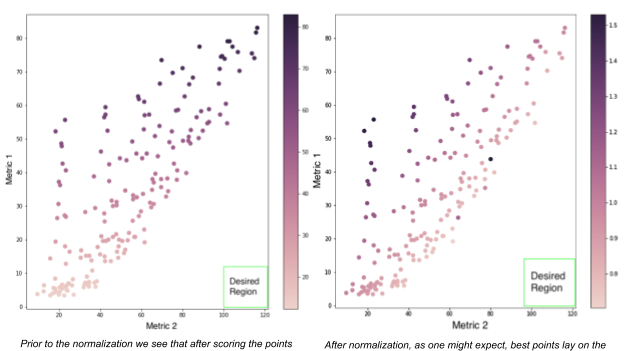
Many optimizers only support functions that return a single value. This means if a game tracks multiple output metrics, we need to evaluate each one individually and then aggregate these scores into one value, which can result in a bias after the aggregation step. Depending on the scale of the metric and the scoring function, some metrics could overpower the others, leading to unexpected results.
One of my tasks was to analyze scoring functions and minimize the influence of such bias on the optimization. To do so, I designed and tested many functions and observed their behavior on different datasets. The best scoring function would gradually approach the desired region and not be biased towards any one metric.


After that, I also experimented with dynamic normalization approaches, which are a bit more complex but yielded great results.

For the game builds, using the Vizier framework the number of executed parameter combinations required to satisfy the desired metric ranges was reduced by 65% compared to random search and by 81% compared to an exhaustive grid search. I also observed that this gap in performance tends to grow with the size of the parameter space, promising efficient searches for complex games. As a result of this experimentation, I identified a scoring function that would help Vizier select parameter combinations that minimize bias from multiple target metrics. I also identified properties of the underlying Vizier algorithm that would help design a more robust service in the future.
Our 2021 Internship Program
Our 2020 Summer Interns were a fantastic addition to the ML-Agents and Game Simulation teams (some of whom will return next year as full-time team members or for another internship). We will continue to expand our internship program in Summer 2021. If you want the opportunity to work on an aspirational project that will impact the experiences of millions of players, please apply!
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies