Unity AI に関するブログシリーズ







AI に関する新しいブログシリーズへようこそ!このシリーズでは、人工知能(AI)と機械学習(ML)に関する Unity の取り組みをご紹介します。過去数年間の機械学習の進化は、オブジェクトの検知やテキストの翻訳、音声認識、ゲームのプレイなど、様々な分野にブレイクスルーをもたらしました。中でもゲームのプレイ(ML とゲームの接点)は、Unity にとって非常に関連性の高い重要な分野です。ディープラーニング(深層学習)におけるブレイクスルーは、テクスチャや 3D モデルの作成方法から非プレイヤーキャラクター(NPC)のプログラミング方法、キャラクターのアニメーション化やシーンのライティングに対する考え方に至るまで、あらゆる面に変化をもたらし、ゲームの開発方法を大きく変革させるでしょう。本ブログシリーズは、こうした新しい技術を模索するためのクリエイティブなスペースとしてご提供できればと考えています。
このブログシリーズは誰のためのもの?
本シリーズの目的は、Unity をお使いのゲーム開発者の皆様に、AI と ML を用いたゲーム開発のアプローチの有効性をお伝えすることです。またアーティストの皆様には、AI 技術をどのようにコンテンツ制作に活用できるかご紹介し、ML 研究者の皆様には、AI 研究・開発用プラットフォームとしての Unity の可能性(各業界におけるロボティクスや自動運転車のシミュレーションプラットフォームとしての Unity の活用など)をお伝えしたいと考えています。さらに本シリーズを通して、愛好家や学生の方々にも Unity と ML への興味をより一層深めていただけることを願っています。
今後数か月間にわたって、本シリーズを通して、こうしたコンセプトや Unity のユースケースに関するディスカッションを開始し、コミュニティーを構築していきたいと考えています。Unity ML チームの複数のメンバーや他の関連チームが、Unity と機械学習の様々な接点について投稿をお届けして参ります。各記事でご紹介する考え方やアルゴリズム、メソッドを、上記のような様々な読者の方々に使用していただけるように、可能な場合は、オープンソースのツールや動画、サンプルプロジェクトも公開して参ります。ぜひ本シリーズをご活用のうえ、お気軽にコメントをご投稿ください。
機械学習の利点
シリーズ第一回となる本記事ではまず、ML とゲーム AI の関係についてお話します。今日存在するほとんどのゲーム AI はハンドコーディングされており、場合によって何千もの規則を含むこともある決定木から構成されています。その全ては手作業で維持され、十分にテストされる必要があります。これと対照的に ML は、生データを解釈できるアルゴリズムに依存しており、データの解釈を定義するエキスパートを必要としません。
例えば、画像のコンテンツ分類におけるコンピュータービジョンの問題を考えてみましょう。数年前までは、例えば、ある画像を「猫や犬を含む」画像として分類する場合、その分類に使用できる「特徴」を抽出するフィルターをエキスパートが手作業で記述していました。一方で、ML(特に最近の深層学習によるアプローチ)では、必要となるのは画像とクラスラベルのみで、分類に使用する「特徴」は自動的に学習されます。この「自動学習」は、より幅広い文脈([例]ML シナリオのシミュレーションなど)における Unity プラットフォーム活用の可能性を拓くだけでなく、大・小規模のゲーム開発者の皆様の制作プロセスを単純化・高速化する一助となるでしょう。
この自動学習は、具体的には、ゲームエージェントの挙動(NPC)に適用可能です。強化学習(Reinforcement Learning/RL)を使用すると、各アクションを取ることの価値を予測するようにエージェントを環境内でトレーニングすることができます。トレーニングされたエージェントは、どのように行動すべきかを明示的にプログラムされなくとも、最大の価値を受け取るアクションを取れるようになります。以下では、強化学習(RL)の簡単な紹介と、簡単な RL アルゴリズムを Unity で実装する方法のウォークスルーをお届けします!そしてもちろん、本記事内で使用した全てのコードはこちらの GitHub レポジトリからご入手いただけます。また、WebGL デモもぜひご利用ください。
バンディットを使用した強化学習
上述の通り、RL の背景にある中心概念は、価値の予測と、予測された価値に基づいて行動する(アクションを実行する)ことです。ここでまず、役に立つ用語をご紹介します。RL では、アクションを実行する主体はエージェントと呼ばれ、これが方策を使用してアクションを決定します。エージェントは常に環境内に組み込まれており、どの時点においても、特定の状態にあります。エージェントはこの状態において一式のアクションのうちのひとつを実行できます。ある状態の価値とは「その状態にいることによって最終的にどれだけの報酬を得られるか」を指します。ある状態においてアクションが実行されると、エージェントに新しい状態がもたらされるか、報酬が提供されるか、あるいはその両方が起こります。全ての RL エージェントの目標は、時間と共に累計報酬を最大化することです。


RL の問題の最も単純なバージョンは多腕バンディットと呼ばれます。この名前は、複数のスロットマシーンにわたってペイアウトを最適化する問題に由来するものです(スロットマシーンは「ユーザーからコインを盗む」傾向から「片腕バンディット」とも呼ばれています)。このセットアップでは、環境はただひとつの状態によって構成され、エージェントは n 個のアクションのうちひとつを実行できます。各アクションはエージェントに即時報酬を提供します。エージェントの目的は、最大の報酬を提供するアクションの選択を学習することです。
具体的な例として、ダンジョンアドベンチャーゲーム内のシナリオを想像してみましょう。エージェントが部屋に入り、壁沿いに並んだいくつかの宝箱を見付けます。これらの宝箱のそれぞれには、一定の確率で、ダイヤモンド(+1 の報酬)か敵のゴースト(-1 の報酬)が入っています。
エージェントの目的は、ダイヤモンドの入っている確立が最も高い宝箱を学習すること(例えば「右から 3 つ目」など)です。どの宝箱の報酬が最も大きいかを学ぶ自然な方法は、それぞれの宝箱を「試す」ことです。実際に、エージェントが十分に環境を学習して最適な形で行動できるようになるまでは、RL の大部分は単純なトライアル・アンド・エラーで構成されます。この例を RL 用語を使って言い表すと、「各宝箱を試す」とは一連のアクション(各宝箱を繰り返し開ける)の実行、「学習」とは各アクションの予測価値の更新を指します。価値予測の精度がある程度高くなれば、常に予測価値の最も高い宝箱をエージェントに選択させることが可能となります。


こうした予測価値は、インタラクティブなプロセス(一連の初期の予測価値 V(a) から開始し、その後アクション実行の度にそれらを調整して結果を観測する)を使用して学習が可能です。これは公式としては以下のように表わされます。

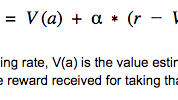
直感的には、上記の方程式は、獲得された報酬の方向に現在の予測価値を若干調整するということを表しています。こうすることで、環境の実際の状態がより正確に反映されるように予測を常に変化させることができます。またこれにより、予測が不必要に大きくなるのを防ぐこともできます(単純に望ましい結果だけを考慮した場合は予測が不必要に大きくなる可能性があります)。コード内でこれを行うには、予測価値の 1 つのベクターを保持し、エージェントの実行したアクションのインデックスによって、これらの予測価値を参照します。


コンテクスチュアルバンディット
上述の状況には、現実的な環境における重要な要素が欠如しています。つまり、状態がひとつしかありません。現実世界(およびゲーム世界)の環境では、数十(家の中の部屋を想像してください)から数十億(画面のピクセル構成)の状態が存在し得ます。その状態のそれぞれが、(アクションによってどのように新しい報酬が与えられたり状態間の切り替えが引き起こされるかに関して)固有の特性(条件)を有し得ます。このため、各状態におけるアクションと、ひいては予測価値の調整も行う必要があります。表記的には、V(a)だけではなく Q(s, a)を使用することになります。抽象的には、受け取る見込みの報酬が、実行するアクションとそのアクションを実行した時点における状態の両方の関数となります。このダンジョンゲームでは、状態の概念によって、異なる部屋に異なる宝箱のセットを置くことが可能になります。部屋ごとに「最適な宝箱」が異なり得るので、エージェントは部屋ごとに異なるアクションを選択することを学習する必要があります。コード内では、単に 1 つのベクターではなく、予測価値の行列を保持することでこれを実現できます。この行列は [state, action] でインデックス付けできます。
探索と搾取
RL をうまく機能させるためには、もうひとつ重要なことがあります。エージェントが「最も報酬の大きいアクションを実行する」ための方策を学習するには、まず、エージェントが「最善」とは何かを理解するのに必要な量の環境学習を十分に行えるようにする方策が必要です。ここで私達は、探索(トライアル・アンド・エラーによって環境の価値構造を学習する)と搾取(学習された環境の価値構造に基づいて行動する)のバランスを取らなければならないという典型的なジレンマに直面します。これらの 2 つの目的は一致することもありますが、往々にして一致しません。2 つの目的のバランスを取るための方法はいくつかあります。以下に、3 つのアプローチをおおまかにご紹介します。
- 単純で強力なひとつの方法は、「不確実な時は楽観的に」という原理に従うことです。これは、エージェントがアクションごとに高い予測価値 V(a) から開始するというもので、この場合、貪欲に行動する(最大の価値をもたらすアクションを実行する)ことによって、エージェントが各アクションを最低 1 回は探索するようになります。アクションの結果、大きな報酬がもたらされなかった場合は、それに応じて予測価値が減少しますが、もたらされた場合は(そのアクションは後に再度試みる有力な候補たり得るので)予測価値は高いまま維持されます。しかしこのヒューリスティックは往々にして、それだけでは不十分です。なぜなら、頻度が低いが大きな報酬を見付けるために、特定の状態を探索し続けなければならなくなる可能性があるからです。
- もうひとつの方法は、各アクションの予測価値にランダムなノイズを追加し、ノイズを含んだ新しい予測に基づいて貪欲に行動するというものです。この方法では、ノイズが真に最善のアクションと他のアクションとの違いより小さい限りは、最善の予測価値に収束することになります。
- さらに一歩踏み込んで、予測価値をそのまま正規化して確率的にアクションを実行するという方法もあります。この方法では、各アクションの予測価値が概ね同等だった場合、アクションも同等の確率で実行されます。逆に、ひとつのアクションの予測価値が大幅に高かった場合は、そのアクションがより頻繁に選択されます。この結果、報酬の少ないアクションの実行される回数が徐々に減少して無くなります。これが、デモプロジェクトで使用されている方法です。
今後の予定
本記事(および補足でご提供したコード)によって、皆様が Unity でコンテクスチュアル多腕バンディットの導入を開始していただくために必要なピースは全て揃いました。ただし、これは始まりに過ぎません。今後のフォローアップ記事では完全な RL 問題における Q 学習 についてご紹介し、続いて、ディープニューラルネットワークを使用して、豊かなビジュアルを備えたゲーム環境における非常に複雑なエージェント挙動のための方策の学習についてお届けして参ります。こうした高度なメソッドを使用すれば、戦闘ゲームや運転ゲームから FPS やリアルタイムストラテジーゲームに至るまで幅広いジャンルで、仲間あるいは敵として機能できるエージェントをトレーニングすることが可能です。そしてこの全てを規則を記述せずに行えるのみならず、エージェントに「目的をどう達成させるか」ではなく「何を目的として達成させたいか」に集中することができます。
今後数回の記事にわたって、Unity を深層強化学習の研究に導入されることをご検討されるリサーチャーの皆様に向けて、TensorFlow や PyTorch などのフレームワークを使用して記述されたモデルを Unity で作成した環境に接続できるようにする各種ツールの早期リリースもご提供して参ります。さらに今年は、エージェントの挙動に関わるものだけでなく、他にも様々な計画が進んでいます。コミュニティーの皆様とともにゲーム開発の未来という未知の領域を探索して行ければ嬉しく思います!
本ブログシリーズの第 2 回はこちらでお読みいただけます。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies