Unity Computer Vision Datasets를 사용한 데이터 중심 AI





프로덕션 AI 시스템을 개발하는 것은 쉬운 일이 아니지만, 높은 투자 수익(ROI)으로 인해 많은 회사에서 프로덕션 애플리케이션과 시스템에 머신러닝(ML) 기반 컴퓨터 비전 기능을 추가하고 있습니다. 유니티는 고객의 제품 출시를 앞당기고 컴퓨터 비전 시스템 품질을 개선하기 위해 데이터 중심 AI 개발 기능을 더욱더 개선하고 있습니다. 이번 포스팅에서는 Unity Computer Vision Datasets를 사용하여 훈련 데이터가 제한적인 ML 모델을 기준 지표에 비해 28% 상대적으로 개선한 방법을 자세히 알아보세요.
Unity Computer Vision Datasets는 데이터가 부족한 컴퓨터 비전 애플리케이션을 위한 솔루션입니다. 훈련 데이터 세트의 규모를 키울 수 있도록 특별히 설계된 커스텀 데이터 제너레이터를 구축할 수 있습니다. 이후 데이터 실험을 진행하면서 타겟 지표를 개선하고, 제품 출시 시간을 단축할 수 있게 됩니다.
이전 블로그 포스팅에서는 사생활 보호 문제로 인해 가정 환경에서 작동하는 컴퓨터 비전 기능에 데이터 수집이 원활하지 않은 이유에 대해 설명했습니다. 유니티는 제품을 테스트하기 위해 초기에 제한적인 실제 데이터 세트로 훈련된 모델의 성능을 개선해 보기로 했습니다.
유니티에서 선택한 사용 사례는 가정 환경에서 강아지를 감지하는 스마트 카메라 애플리케이션 기능입니다. 특히 가정 환경에 거주하는 강아지에 집중하기 위해 소파와 전자레인지, 헤어드라이어 등 일반적인 가정용품과 강아지가 함께 등장하는 COCO 및 OIDSv6 이미지 데이터 세트의 일부를 사용했습니다. 바운딩 박스로 레이블이 지정된 1,538장의 강아지 이미지를 데이터 세트로 사용했으며, 이 중 1,200장은 훈련 이미지로, 200장은 테스트 이미지로, 138장은 검증 이미지로 사용했습니다.
기준 모델과 지표 설정
첫 번째 목표는 실제 데이터만 사용해 기준 모델과 측정 지표를 만드는 것이었습니다. 쉽게 구할 수 있는 ImageNet 가중치로 사전 훈련된 Detectron2의 Faster RCNN 아키텍처를 사용했습니다. 단일 클래스 오브젝트 감지 작업에 사용한 지표는 0.05의 단계 크기로 0.5부터 0.95까지의 IoU(Intersection over Union)에 대한 평균 AP(Average Precision)와 AR(Average Recall)입니다. 하나의 클래스만 감지했기 때문에 mAP, mAR이 아닌 AP, AR을 사용했습니다. 극단적인 사례에서와 같이 제한된 훈련 데이터만 사용했기 때문에 성능 기준을 AP는 51.16으로, AR은 50.3으로 설정했습니다. 이 단계에서는 모델 최적화를 전혀 진행하지 않았으며, 최우선 목표는 모델을 고정하고 정해진 데이터에 대해서만 반복 작업을 진행하여 기준을 개선하는 것이었습니다.
1단계: Unity Computer Vision Datasets를 사용한 지표 개선
콘텐츠 제작 팀은 Unity Computer Vision Datasets 서비스로 조명과 배치 무작위화와 같은 노출된 파라미터를 사용해 환경을 제작하여 ML 개발자가 실험을 위한 데이터를 설정하고 생산하도록 했습니다. 데이터 제너레이터를 퍼블리시한 후 ML 개발 팀은 데이터 세트를 생성하고 모델을 다시 훈련했습니다. 합성 데이터 세트에 대한 사전 훈련과 실제 데이터 세트에 대한 미세 조정을 수행한 많은 프로젝트에서 긍정적인 결과를 보인 사례를 따라 진행했습니다. 그 결과, 두 지표 모두 개선되어 AP가 56.83, AR이 55.1이라는 새로운 결과를 얻었습니다.


2단계: 개선된 합성 데이터 세트를 빠르게 생성
몇 가지 기본적인 분포 분석을 진행하여 여러 차원에서 합성 데이터 세트와 실제 데이터 세트의 분포를 비교하고 성능 저하로 이어질 수 있는 우려 사항이 있는지 확인했습니다. 2D 이미지 내에서 강아지의 위치 분포를 비교했을 때 아래 그림처럼 실제 데이터 세트와 합성 데이터 세트 사이에 두드러지는 차이를 발견했습니다.
강아지 위치 분포 히트맵
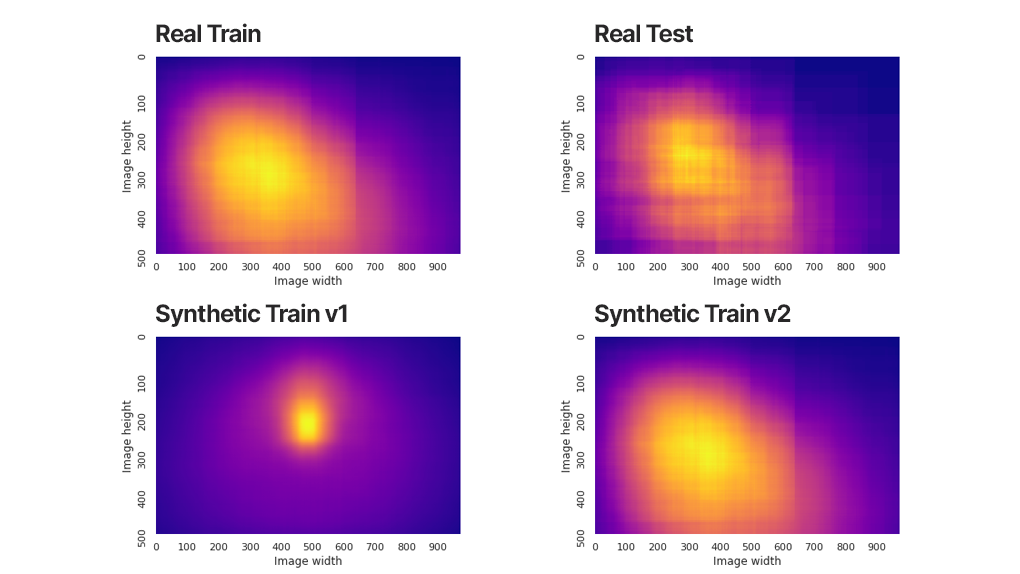
이 정보만으로는 합성 훈련 데이터에서 강아지의 위치에 대한 좁은 분포가 타겟 지표에 영향을 미쳤다고 결론을 내릴 수 없었습니다. 이에 따라 분포를 넓히는 것이 지표에 영향을 주는지 확인하고자 빠르게 실험을 진행했습니다. Unity Computer Vision Datasets의 합성 데이터 제너레이터가 카메라를 기준으로 3D 위치상 배치와 관련된 파라미터를 노출했기 때문에, ML 개발자는 Unity 프로젝트를 변경하지 않고도 30분 내로 2D 이미지 내에서 강아지의 위치를 훨씬 다양하게 바꾼 새로운 데이터 세트를 생성할 수 있었습니다.
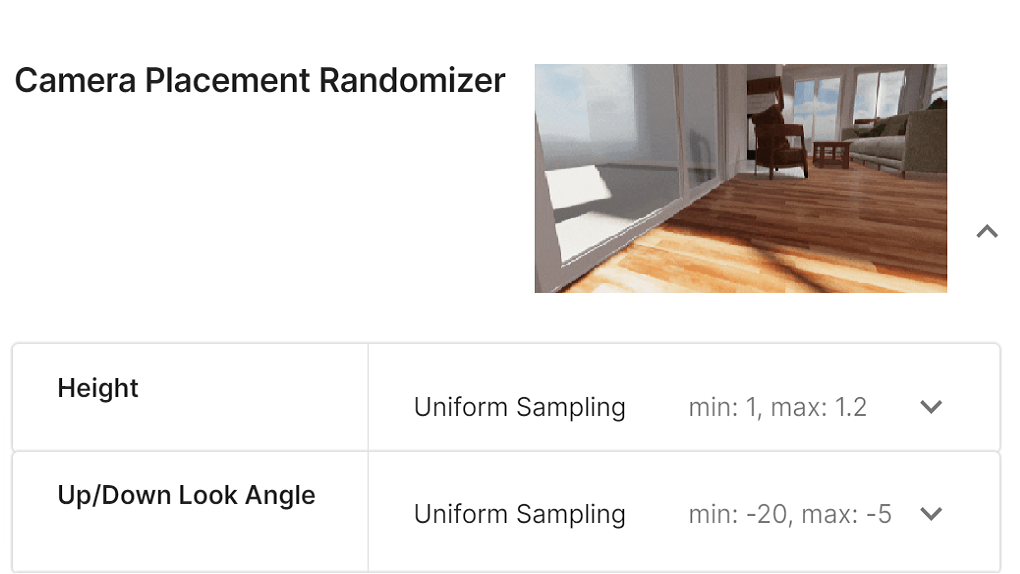
팀은 새로운 데이터 세트(v2)를 기반으로 모델을 다시 훈련했으며, AP는 57.18로 조금 개선되었고 AR은 같은 값을 보였습니다.
3단계: 더 큰 데이터 세트를 사용한 빠른 실험
2단계까지 진행하면서 데이터 생성 전략과 파라미터에 익숙해진 후 데이터 세트의 크기를 키우기로 했습니다. Unity Computer Vision Datasets를 사용하면 같은 설정으로 더 큰 데이터 세트를 손쉽게 생성할 수 있었습니다. 유니티는 4만 장의 이미지가 포함된 데이터 세트 하나와 10만 장의 이미지가 포함된 데이터 세트 하나를 만들기로 결정했습니다.
Unity Computer Vision Datasets는 Unity의 실시간 렌더링 엔진을 기반으로 하며, 클라우드에서 데이터 생성을 수평 스케일링하여 90분도 채 되지 않는 시간 안에 10만 장의 이미지로 구성된 사실적인 데이터 세트를 생성할 수 있습니다. 모델을 다시 훈련한 후, 더 큰 데이터 세트로 꾸준히 결과가 개선되는 것을 확인할 수 있습니다.

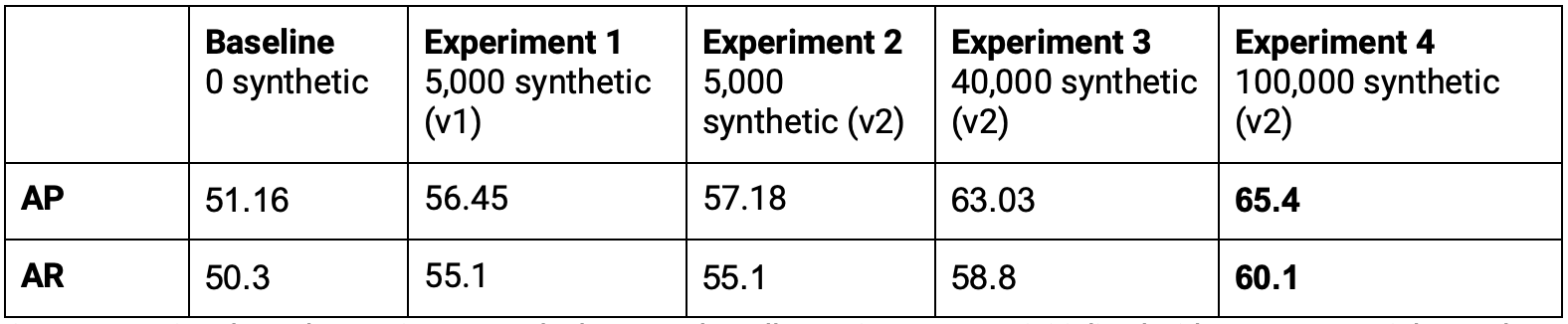
곧바로 프로덕션 시스템에 배포할 수 있는 모델은 아니었지만, 모델을 고정한 채로 정해진 데이터에 대해서만 반복 작업을 진행하여 빠르게 주요 지표인 AP를 14 이상 개선하고 AR을 약 10 정도 개선할 수 있었습니다. 또한 10만 장의 이미지 데이터 세트를 생성하고 업데이트된 모델을 훈련하는 전체 과정을 5시간 이내에 완료했습니다. 데이터 중심 AI를 이용하면 빠르게 모델을 개선할 수 있습니다.
Github Sample Project
Please refer to this project which we used majorly for training the above mentioned experiments. The project provides scripts necessary for the specific use case of dog detection in an indoor home environment, as well as instructions on how to generate synthetic data for it using Unity Computer Vision Datasets. And after generating the required datasets, how to train & evaluate a model.
We have all the model checkpoint released, which were used for running our experiments, with different strategies around the amount of synthetic data. You can find all the experiments with their results for each checkpoint here.
If you want to try it out yourself please check out our space here.
마무리
Unity Computer Vision Datasets는 합성 데이터 개발자와 머신러닝 팀의 협업을 강력하게 지원하여 합성 데이터 실험의 반복 작업 속도를 개선합니다. 합성 데이터를 사용한 실험을 더 빠르게 반복하면 최상의 결과를 만들어 내는 최고의 데이터 세트를 더 빠르게 생성할 수 있습니다.
Unity Computer Vision Datasets에서 현재 지원하는 기능은 아래와 같습니다.
- 커스텀 '데이터 제너레이터' - 유니티의 실시간 3D 및 머신러닝 전문가가 사용 사례에 맞는 커스텀 데이터 제너레이터를 제작하여 조직 내에서 사용할 수 있도록 지원합니다. 서비스에 대한 자세한 내용은 문의하시기 바랍니다.
- 파라메트릭 합성 데이터 세트 생성 - 지속적인 반복 작업과 실험을 위해 사전 제작된 파라메트릭 환경에 대한 데이터 세트를 생성합니다.
- 합성 데이터 세트 호스팅 - 하나의 프로젝트에 대한 여러 합성 데이터 세트를 관리합니다.
- 데이터 세트 시각화 - 실측 자료 레이블을 사용해 데이터 세트를 시각화합니다.
- 다운로드 및 전송 - 데이터 세트를 로컬 스토리지에 다운로드하거나 Google Cloud Storage 버킷으로 다운로드할 수 있습니다.
- 무료 데이터 생성 - 사전 제작된 환경(일반 물체 감지, 홈 인테리어, 상점)에서 최대 10,000장의 이미지를 생성할 수 있습니다.
지금 Unity Computer Vision Datasets에 가입하여 샘플 데이터 세트를 살펴보고 사전 제작된 환경에서 직접 샘플 데이터 세트를 생성해 보세요.
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies